11.2. 類似度によるアテンションプーリング¶
他にも多くの選択肢がある。より詳しい概説と、カーネルの選択がカーネル密度推定、しばしば Parzen Windows とも呼ばれるもの (Parzen, 1957) とどう関係するかについては、Wikipedia の記事 を参照されたい。これらのカーネルはいずれもヒューリスティックであり、調整可能である。たとえば、幅は全体としてだけでなく、各座標ごとにも調整できる。いずれにせよ、どれも回帰と分類の両方に対して次の式を導く。
特徴量とラベルの観測 \((\mathbf{x}_i, y_i)\) を用いる(スカラー)回帰の場合、\(\mathbf{v}_i = y_i\) はスカラー、\(\mathbf{k}_i = \mathbf{x}_i\) はベクトルであり、クエリ \(\mathbf{q}\) は \(f\) を評価すべき新しい位置を表す。(多クラス)分類の場合は、\(y_i\) の one-hot エンコーディングを用いて \(\mathbf{v}_i\) を得る。この推定量の便利な性質の一つは、学習を必要としないことである。さらに、データ量の増加に応じてカーネルを適切に狭めれば、この手法は整合的であり (Mack and Silverman, 1982)、すなわち統計的に最適な解のいずれかに収束する。まずはいくつかのカーネルを見てみよう。
from d2l import torch as d2l
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
d2l.use_svg_display()
from d2l import mxnet as d2l
from mxnet import autograd, gluon, np, npx
from mxnet.gluon import nn
npx.set_np()
d2l.use_svg_display()
from d2l import jax as d2l
import jax
from jax import numpy as jnp
from flax import linen as nn
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
from d2l import tensorflow as d2l
import tensorflow as tf
import numpy as np
d2l.use_svg_display()
11.2.1. カーネルとデータ¶
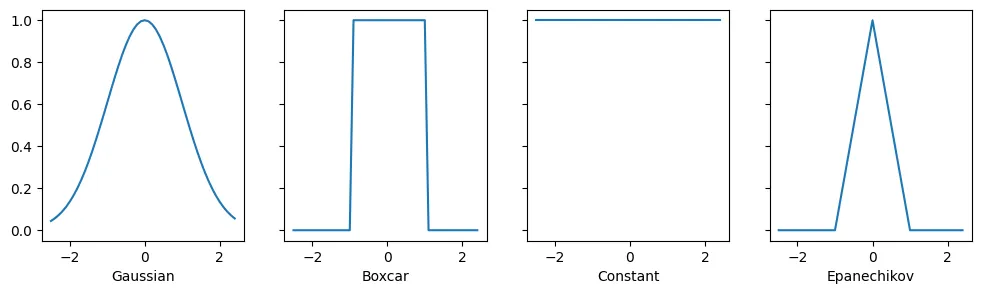
この節で定義するすべてのカーネル \(\alpha(\mathbf{k}, \mathbf{q})\) は 平行移動および回転に不変 である。つまり、\(\mathbf{k}\) と \(\mathbf{q}\) を同じように平行移動・回転させても、\(\alpha\) の値は変わらない。簡単のため、ここではスカラー引数 \(k, q \in \mathbb{R}\) を取り、キー \(k = 0\) を原点として選ぶ。すると次のようになる。
# いくつかのカーネルを定義する
def gaussian(x):
return d2l.exp(-x**2 / 2)
def boxcar(x):
return d2l.abs(x) < 1.0
def constant(x):
return 1.0 + 0 * x
def epanechikov(x):
return torch.max(1 - d2l.abs(x), torch.zeros_like(x))
# いくつかのカーネルを定義する
def gaussian(x):
return d2l.exp(-x**2 / 2)
def boxcar(x):
return d2l.abs(x) < 1.0
def constant(x):
return 1.0 + 0 * x
def epanechikov(x):
return np.maximum(1 - d2l.abs(x), 0)
# いくつかのカーネルを定義する
def gaussian(x):
return d2l.exp(-x**2 / 2)
def boxcar(x):
return d2l.abs(x) < 1.0
def constant(x):
return 1.0 + 0 * x
def epanechikov(x):
return jnp.maximum(1 - d2l.abs(x), 0)
# いくつかのカーネルを定義する
def gaussian(x):
return d2l.exp(-x**2 / 2)
def boxcar(x):
return d2l.abs(x) < 1.0
def constant(x):
return 1.0 + 0 * x
def epanechikov(x):
return tf.maximum(1 - d2l.abs(x), 0)
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
kernels = (gaussian, boxcar, constant, epanechikov)
names = ('Gaussian', 'Boxcar', 'Constant', 'Epanechikov')
x = d2l.arange(-2.5, 2.5, 0.1)
for kernel, name, ax in zip(kernels, names, axes):
ax.plot(d2l.numpy(x), d2l.numpy(kernel(x)))
ax.set_xlabel(name)
d2l.plt.show()

fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
kernels = (gaussian, boxcar, constant, epanechikov)
names = ('Gaussian', 'Boxcar', 'Constant', 'Epanechikov')
x = d2l.arange(-2.5, 2.5, 0.1)
for kernel, name, ax in zip(kernels, names, axes):
ax.plot(d2l.numpy(x), d2l.numpy(kernel(x)))
ax.set_xlabel(name)
d2l.plt.show()
[07:07:20] ../src/storage/storage.cc:196: Using Pooled (Naive) StorageManager for CPU

fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
kernels = (gaussian, boxcar, constant, epanechikov)
names = ('Gaussian', 'Boxcar', 'Constant', 'Epanechikov')
x = d2l.arange(-2.5, 2.5, 0.1)
for kernel, name, ax in zip(kernels, names, axes):
ax.plot(x, kernel(x))
ax.set_xlabel(name)
d2l.plt.show()
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
kernels = (gaussian, boxcar, constant, epanechikov)
names = ('Gaussian', 'Boxcar', 'Constant', 'Epanechikov')
x = d2l.arange(-2.5, 2.5, 0.1)
for kernel, name, ax in zip(kernels, names, axes):
ax.plot(d2l.numpy(x), d2l.numpy(kernel(x)))
ax.set_xlabel(name)
d2l.plt.show()

異なるカーネルは、範囲と滑らかさに関する異なる概念に対応する。たとえば、boxcar カーネルは距離 \(1\)(あるいは別に定義したハイパーパラメータ)以内の観測値にしか注目せず、しかもそれを無差別に行う。
Nadaraya–Watson 推定を実際に見てみるために、訓練データを定義しよう。以下では次の依存関係を用いる。
ここで \(\epsilon\) は平均 0、分散 1 の正規分布から生成される。40 個の訓練例をサンプルする。
def f(x):
return 2 * d2l.sin(x) + x
n = 40
x_train, _ = torch.sort(d2l.rand(n) * 5)
y_train = f(x_train) + d2l.randn(n)
x_val = d2l.arange(0, 5, 0.1)
y_val = f(x_val)
def f(x):
return 2 * d2l.sin(x) + x
n = 40
x_train = np.sort(d2l.rand(n) * 5, axis=None)
y_train = f(x_train) + d2l.randn(n)
x_val = d2l.arange(0, 5, 0.1)
y_val = f(x_val)
def f(x):
return 2 * d2l.sin(x) + x
n = 40
x_train = jnp.sort(jax.random.uniform(d2l.get_key(), (n,)) * 5)
y_train = f(x_train) + jax.random.normal(d2l.get_key(), (n,))
x_val = d2l.arange(0, 5, 0.1)
y_val = f(x_val)
def f(x):
return 2 * d2l.sin(x) + x
n = 40
x_train = tf.sort(d2l.rand((n,1)) * 5, 0)
y_train = f(x_train) + d2l.normal((n, 1))
x_val = d2l.arange(0, 5, 0.1)
y_val = f(x_val)
11.2.2. Nadaraya–Watson 回帰によるアテンションプーリング¶
データとカーネルがそろったので、あとはカーネル回帰の推定値を計算する関数だけである。なお、簡単な診断を行うために相対的なカーネル重みも得たいので、まず訓練特徴(共変量)x_train
とすべての検証特徴 x_val
の間のカーネルを計算する。これにより行列が得られ、それを正規化する。これを訓練ラベル
y_train と掛け合わせると推定値が得られる。
(11.1.1)
のアテンションプーリングを思い出してほしい。各検証特徴をクエリとし、各訓練特徴–ラベルの組をキー–値のペアとみなす。その結果、正規化された相対カーネル重み(以下の
attention_w)が アテンション重み になる。
def nadaraya_watson(x_train, y_train, x_val, kernel):
dists = d2l.reshape(x_train, (-1, 1)) - d2l.reshape(x_val, (1, -1))
# 各列/行はそれぞれのクエリ/キーに対応する
k = d2l.astype(kernel(dists), d2l.float32)
# 各クエリに対するキー方向の正規化
attention_w = k / d2l.reduce_sum(k, 0)
y_hat = y_train@attention_w
return y_hat, attention_w
def nadaraya_watson(x_train, y_train, x_val, kernel):
dists = d2l.reshape(x_train, (-1, 1)) - d2l.reshape(x_val, (1, -1))
# 各列/行はそれぞれのクエリ/キーに対応する
k = d2l.astype(kernel(dists), d2l.float32)
# 各クエリに対するキー方向の正規化
attention_w = k / d2l.reduce_sum(k, 0)
y_hat = np.dot(y_train, attention_w)
return y_hat, attention_w
def nadaraya_watson(x_train, y_train, x_val, kernel):
dists = d2l.reshape(x_train, (-1, 1)) - d2l.reshape(x_val, (1, -1))
# 各列/行はそれぞれのクエリ/キーに対応する
k = d2l.astype(kernel(dists), d2l.float32)
# 各クエリに対するキー方向の正規化
attention_w = k / d2l.reduce_sum(k, 0)
y_hat = y_train@attention_w
return y_hat, attention_w
def nadaraya_watson(x_train, y_train, x_val, kernel):
dists = d2l.reshape(x_train, (-1, 1)) - d2l.reshape(x_val, (1, -1))
# 各列/行はそれぞれのクエリ/キーに対応する
k = d2l.astype(kernel(dists), d2l.float32)
# 各クエリに対するキー方向の正規化
attention_w = k / d2l.reduce_sum(k, 0)
y_hat = d2l.transpose(d2l.transpose(y_train)@attention_w)
return y_hat, attention_w
異なるカーネルがどのような推定を生み出すか見てみよう。
def plot(x_train, y_train, x_val, y_val, kernels, names, attention=False):
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
for kernel, name, ax in zip(kernels, names, axes):
y_hat, attention_w = nadaraya_watson(x_train, y_train, x_val, kernel)
if attention:
pcm = ax.imshow(d2l.numpy(attention_w), cmap='Reds')
else:
ax.plot(x_val, y_hat)
ax.plot(x_val, y_val, 'm--')
ax.plot(x_train, y_train, 'o', alpha=0.5);
ax.set_xlabel(name)
if not attention:
ax.legend(['y_hat', 'y'])
if attention:
fig.colorbar(pcm, ax=axes, shrink=0.7)
def plot(x_train, y_train, x_val, y_val, kernels, names, attention=False):
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
for kernel, name, ax in zip(kernels, names, axes):
y_hat, attention_w = nadaraya_watson(x_train, y_train, x_val, kernel)
if attention:
pcm = ax.imshow(d2l.numpy(attention_w), cmap='Reds')
else:
ax.plot(x_val, y_hat)
ax.plot(x_val, y_val, 'm--')
ax.plot(x_train, y_train, 'o', alpha=0.5);
ax.set_xlabel(name)
if not attention:
ax.legend(['y_hat', 'y'])
if attention:
fig.colorbar(pcm, ax=axes, shrink=0.7)
def plot(x_train, y_train, x_val, y_val, kernels, names, attention=False):
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
for kernel, name, ax in zip(kernels, names, axes):
y_hat, attention_w = nadaraya_watson(x_train, y_train, x_val, kernel)
if attention:
pcm = ax.imshow(attention_w, cmap='Reds')
else:
ax.plot(x_val, y_hat)
ax.plot(x_val, y_val, 'm--')
ax.plot(x_train, y_train, 'o', alpha=0.5);
ax.set_xlabel(name)
if not attention:
ax.legend(['y_hat', 'y'])
if attention:
fig.colorbar(pcm, ax=axes, shrink=0.7)
def plot(x_train, y_train, x_val, y_val, kernels, names, attention=False):
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
for kernel, name, ax in zip(kernels, names, axes):
y_hat, attention_w = nadaraya_watson(x_train, y_train, x_val, kernel)
if attention:
pcm = ax.imshow(d2l.numpy(attention_w), cmap='Reds')
else:
ax.plot(x_val, y_hat)
ax.plot(x_val, y_val, 'm--')
ax.plot(x_train, y_train, 'o', alpha=0.5);
ax.set_xlabel(name)
if not attention:
ax.legend(['y_hat', 'y'])
if attention:
fig.colorbar(pcm, ax=axes, shrink=0.7)
plot(x_train, y_train, x_val, y_val, kernels, names)

まず目につくのは、3 つの非自明なカーネル(Gaussian、Boxcar、Epanechikov)が、真の関数からそれほど離れていない、かなり実用的な推定を与えていることである。自明な推定 \(f(x) = \frac{1}{n} \sum_i y_i\) に帰着する constant カーネルだけが、かなり非現実的な結果を生む。アテンションの重み付けをもう少し詳しく見てみよう。
plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)

この可視化から、Gaussian、Boxcar、Epanechikov の推定が非常によく似ている理由がはっきり分かる。結局のところ、カーネルの関数形は異なっていても、非常によく似たアテンション重みから導されているからである。ここで疑問になるのは、これが常に成り立つのかということである。
11.2.3. アテンションプーリングの適応¶
Gaussian カーネルを別の幅のものに置き換えることができる。つまり、 \(\alpha(\mathbf{q}, \mathbf{k}) = \exp\left(-\frac{1}{2 \sigma^2} \|\mathbf{q} - \mathbf{k}\|^2 \right)\) を使い、\(\sigma^2\) でカーネルの幅を決めることができる。これが結果に影響するか見てみよう。
sigmas = (0.1, 0.2, 0.5, 1)
names = ['Sigma ' + str(sigma) for sigma in sigmas]
def gaussian_with_width(sigma):
return (lambda x: d2l.exp(-x**2 / (2*sigma**2)))
kernels = [gaussian_with_width(sigma) for sigma in sigmas]
plot(x_train, y_train, x_val, y_val, kernels, names)

明らかに、カーネルが狭いほど推定は滑らかでなくなる。同時に、局所的な変動にはよりよく適応する。対応するアテンション重みを見てみよう。
plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)

予想どおり、カーネルが狭いほど、大きなアテンション重みを持つ範囲も狭くなる。また、同じ幅を選ぶことが必ずしも理想的ではないことも明らかである。実際、Silverman (1986) は局所密度に依存するヒューリスティックを提案した。このような「工夫」は他にも多数提案されている。たとえば、Norelli et al. (2022) は、クロスモーダルな画像・テキスト表現を設計するために、類似した最近傍補間技術を用いた。
この方法が半世紀以上前のものであるにもかかわらず、なぜここまで詳しく扱うのか、不思議に思う読者もいるかもしれない。第一に、現代のアテンション機構の最も初期の先駆けの一つだからである。第二に、可視化に非常に適している。第三に、そして同じくらい重要であるが、手作りのアテンション機構の限界を示してくれる。より良い戦略は、クエリとキーの表現を学習することで機構そのものを 学習する ことである。これが次の節で取り組む内容である。
11.2.4. まとめ¶
11.2.5. 演習¶
Parzen windows による密度推定は \(\hat{p}(\mathbf{x}) = \frac{1}{n} \sum_i k(\mathbf{x}, \mathbf{x}_i)\) で与えられる。二値分類に対して、Parzen windows から得られる関数 \(\hat{p}(\mathbf{x}, y=1) - \hat{p}(\mathbf{x}, y=-1)\) が Nadaraya–Watson 分類と等価であることを証明せよ。
Nadaraya–Watson 回帰において、カーネル幅の良い値を学習するための確率的勾配降下法を実装せよ。
上の推定値をそのまま使って \((f(\mathbf{x_i}) - y_i)^2\) を直接最小化するとどうなるか? ヒント: \(y_i\) は \(f\) を計算するために使われる項の一部である。
\(f(\mathbf{x}_i)\) の推定から \((\mathbf{x}_i, y_i)\) を除外し、カーネル幅について最適化せよ。それでも過学習は観測されるか?
すべての \(\mathbf{x}\) が単位球面上にある、すなわちすべて \(\|\mathbf{x}\| = 1\) を満たすと仮定する。指数関数内の \(\|\mathbf{x} - \mathbf{x}_i\|^2\) の項を簡単化できるか? ヒント: 後で、ドット積アテンションと非常に密接に関係していることが分かる。
Mack and Silverman (1982) が Nadaraya–Watson 推定の整合性を証明したことを思い出してほしい。データが増えるにつれて、アテンション機構のスケールをどのくらいの速さで小さくすべきだろうか。 答えの直感も述べよ。データの次元に依存するか? どのように依存するか?