11.9. Transformerによる大規模事前学習¶
これまでの画像分類と機械翻訳の実験では、 モデルは入力–出力の例を含むデータセットで 特定のタスクを実行するために ゼロから 学習されてきた。 たとえば、Transformer は英語–フランス語の対で学習された (11.7 章)。 これにより、このモデルは入力された英語テキストをフランス語に翻訳できる。 その結果、各モデルはデータ分布のわずかな変化にも敏感な 特化型の専門家 になる (4.7 章)。 より汎化性能の高いモデル、あるいは適応の有無にかかわらず複数のタスクを実行できる より有能な 汎用モデル を得るために、 大規模データでモデルを 事前学習 することがますます一般的になっている。
事前学習のためのデータが大きくなると、Transformer アーキテクチャは モデルサイズと学習計算量を増やすことでより良い性能を示し、 優れた スケーリング 挙動を示す。 具体的には、Transformer ベースの言語モデルの性能は、 モデルパラメータ数、学習トークン数、学習計算量に対してべき乗則でスケールする (Kaplan et al., 2020)。 Transformer のスケーラビリティは、 より大きなデータで学習されたより大規模な Vision Transformer による 大幅な性能向上からも裏付けられている (11.8 章 で議論)。 より最近の成功例には Gato があり、 Atari をプレイし、画像にキャプションを付け、会話し、ロボットとして行動できる 汎用 モデルである (Reed et al., 2022)。Gato は、テキスト、画像、関節トルク、ボタン押下など多様なモダリティで事前学習されたときにうまくスケールする単一の Transformer である。 特筆すべきことに、このようなマルチモーダルデータはすべて、平坦なトークン列として直列化され、 Transformer によってテキストトークン (11.7 章) や画像パッチ (11.8 章) と同様に処理できる。
マルチモーダルデータに対する Transformer 事前学習の説得力ある成功に先立って、 Transformer は大量のテキストで広く事前学習されていた。 もともと機械翻訳のために提案された Transformer アーキテクチャは、 図 11.7.1 に示すように、 入力系列を表現するためのエンコーダと、 ターゲット系列を生成するためのデコーダから構成される。 主に、Transformer は 3 つの異なるモードで使用できる: エンコーダのみ、エンコーダ–デコーダ、および デコーダのみ である。 この章の最後に、これら 3 つのモードを概観し、 Transformer の事前学習におけるスケーラビリティを説明する。
11.9.1. エンコーダのみ¶
Transformer エンコーダのみを使用する場合、 入力トークン列は同じ数の表現に変換され、 さらに出力(たとえば分類)へ射影できる。 Transformer エンコーダは自己注意層から構成され、 すべての入力トークンが互いに注意を向ける。 たとえば、 図 11.8.1 に示した Vision Transformer はエンコーダのみであり、 入力画像パッチの列を特別な “<cls>” トークンの表現へ変換する。 この表現はすべての入力トークンに依存するため、 さらに分類ラベルへ射影される。 この設計は、テキストで事前学習された先行のエンコーダのみ Transformer、 BERT (Bidirectional Encoder Representations from Transformers) (Devlin et al., 2018) に着想を得ている。
11.9.1.1. BERT の事前学習¶

図 11.9.1 左: マスク付き言語モデリングによる BERT の事前学習。マスクされた “love” トークンの予測は、“love” の前後にあるすべての入力トークンに依存する。右: Transformer エンコーダにおける注意パターン。縦軸上の各トークンは、横軸上のすべての入力トークンに注意を向ける。¶
BERT は マスク付き言語モデリング を用いてテキスト系列で事前学習される: ランダムにマスクされたトークンを含む入力テキストを Transformer エンコーダに与え、マスクされたトークンを予測する。 図 11.9.1 に示すように、 元のテキスト系列 “I”, “love”, “this”, “red”, “car” の先頭に “<cls>” トークンを付加し、 “<mask>” トークンが “love” をランダムに置き換える。 その後、マスクされたトークン “love” とその予測との間のクロスエントロピー損失を、 事前学習中に最小化する。 Transformer エンコーダの注意パターン (図 11.9.1 の右側) には制約がないため、 すべてのトークンが互いに注意を向けられることに注意されたい。 したがって、“love” の予測は系列中の前後の入力トークンに依存する。 これが BERT が「双方向エンコーダ」である理由である。 手作業のラベル付けを必要とせず、書籍や Wikipedia から得られる大規模テキストデータを BERT の事前学習に利用できる。
11.9.1.2. BERT のファインチューニング¶
事前学習済み BERT は、単一テキストまたはテキスト対を含む下流のエンコーディングタスクに対して ファインチューニング できる。ファインチューニング中には、ランダムに初期化された追加層を BERT に加えることができ、これらのパラメータと事前学習済み BERT のパラメータの両方が、下流タスクの学習データに適合するように 更新 される。

図 11.9.2 感情分析のための BERT のファインチューニング。¶
図 11.9.2 は、 感情分析のための BERT のファインチューニングを示している。 Transformer エンコーダは事前学習済み BERT であり、 テキスト系列を入力として受け取り、 “<cls>” 表現 (入力全体のグローバル表現) を追加の全結合層に入力して 感情を予測する。 ファインチューニング中は、感情分析データにおける 予測とラベルの間のクロスエントロピー損失を、 勾配ベースのアルゴリズムで最小化する。 このとき、追加層はゼロから学習され、 BERT の事前学習済みパラメータは更新される。 BERT は感情分析だけにとどまらない。 3.5 億パラメータの BERT が 2500 億トークンの学習トークンから学んだ 汎用的な言語表現は、 単一テキスト分類、テキスト対分類または回帰、 テキストタグ付け、質問応答などの自然言語タスクにおいて 最先端性能を押し上げた。
これらの下流タスクにはテキスト対理解が含まれることに気づくかもしれない。 BERT の事前学習には、ある文が別の文に直後に続くかどうかを予測する 別の損失がある。 しかし、この損失は、同じサイズの BERT 変種を 2 兆トークンで事前学習した RoBERTa においては、 後にあまり有用ではないことがわかった (Liu et al., 2019)。 BERT の他の派生モデルは、モデルアーキテクチャや事前学習目的を改善した。 たとえば、ALBERT(パラメータ共有を強制) (Lan et al., 2019)、 SpanBERT(テキストのスパンを表現・予測) (Joshi et al., 2020)、 DistilBERT(知識蒸留による軽量化) (Sanh et al., 2019)、 ELECTRA(置換トークン検出) (Clark et al., 2020) などである。 さらに、BERT はコンピュータビジョンにおける Transformer 事前学習にも影響を与え、 Vision Transformer (Dosovitskiy et al., 2021)、 Swin Transformer (Liu et al., 2021)、 MAE(masked autoencoders) (He et al., 2022) などが生まれた。
11.9.2. エンコーダ–デコーダ¶
Transformer エンコーダは入力トークン列を 同じ数の出力表現へ変換するため、 エンコーダのみモードでは機械翻訳のように任意長の系列を生成できない。 もともと機械翻訳のために提案されたように、 Transformer アーキテクチャにはデコーダを組み込むことができ、 デコーダはエンコーダ出力とデコーダ出力の両方を条件として、 ターゲット系列をトークンごとに自己回帰的に予測し、 任意長のターゲット系列を生成する: (i) エンコーダ出力を条件付けするために、エンコーダ–デコーダのクロスアテンション (図 11.7.1 のデコーダのマルチヘッド注意) により、ターゲットトークンは すべて の入力トークンに注意を向けられる; (ii) デコーダ出力を条件付けすることは、いわゆる 因果的 注意 (この名称は文献で一般的であるが、因果性の正しい研究とはほとんど関係がないため誤解を招く) パターン (図 11.7.1 のデコーダのマスク付きマルチヘッド注意) によって実現され、任意のターゲットトークンはターゲット系列中の 過去 と 現在 のトークンにのみ注意を向けられる。
人手ラベル付きの機械翻訳データを超えてエンコーダ–デコーダ Transformer を事前学習するために、 BART (Lewis et al., 2019) と T5 (Raffel et al., 2020) は、 大規模テキストコーパスで事前学習された 2 つの同時期に提案されたエンコーダ–デコーダ Transformer である。 どちらも事前学習目的において元のテキストの復元を試みるが、 前者は入力へのノイズ付加 (たとえば、マスキング、削除、並べ替え、回転)を重視し、 後者は包括的なアブレーション研究とともに マルチタスクの統一を強調している。
11.9.2.1. T5 の事前学習¶
事前学習済み Transformer エンコーダ–デコーダの例として、 T5 (Text-to-Text Transfer Transformer) は多くのタスクを同じ text-to-text 問題として統一する: どのタスクでも、エンコーダの入力はタスク記述 (たとえば “Summarize”, “:”) に続いてタスク入力 (たとえば記事からのトークン列)となり、 デコーダはタスク出力 (たとえば入力記事を要約したトークン列)を予測する。 text-to-text として機能するために、T5 は 入力テキストに条件付けてあるターゲットテキストを生成するよう学習される。

図 11.9.3 左: 連続するスパンを予測することによる T5 の事前学習。元の文は “I”, “love”, “this”, “red”, “car” であり、“love” は特別な “<X>” トークンに置き換えられ、連続する “red”, “car” は特別な “<Y>” トークンに置き換えられる。ターゲット系列は特別な “<Z>” トークンで終わる。右: Transformer エンコーダ–デコーダにおける注意パターン。エンコーダの自己注意(下側の正方形)では、すべての入力トークンが互いに注意を向ける; エンコーダ–デコーダのクロスアテンション(上側の長方形)では、各ターゲットトークンがすべての入力トークンに注意を向ける; デコーダの自己注意(上側の三角形)では、各ターゲットトークンは現在および過去のターゲットトークンのみに注意を向ける(因果的)。¶
任意の元テキストから入力と出力を得るために、 T5 は連続するスパンを予測するよう事前学習される。 具体的には、テキスト中のトークンがランダムに 特別なトークンで置き換えられ、各連続スパンは 同じ特別トークンで置き換えられる。 図 11.9.3 の例を考えよう。 元のテキストは “I”, “love”, “this”, “red”, “car” である。 トークン “love”, “red”, “car” はランダムに特別なトークンで置き換えられる。 “red” と “car” は連続するスパンなので、 同じ特別トークンで置き換えられる。 その結果、入力系列は “I”, “<X>”, “this”, “<Y>” となり、 ターゲット系列は “<X>”, “love”, “<Y>”, “red”, “car”, “<Z>” となる。ここで “<Z>” は終端を示す別の特別トークンである。 図 11.9.3 に示すように、 デコーダは系列予測中に未来のトークンへ注意を向けないよう、 因果的注意パターンを持つ。
T5 では、連続するスパンの予測は 破損したテキストの復元とも呼ばれる。 この目的のもと、T5 は C4 (Colossal Clean Crawled Corpus) データからの 1000 億トークンで事前学習された。 このデータはウェブ上のクリーンな英語テキストから構成されている (Raffel et al., 2020)。
11.9.2.2. T5 のファインチューニング¶
BERT と同様に、T5 もこのタスクを実行するために、 タスク固有の学習データでファインチューニング(T5 パラメータの更新)する必要がある。 BERT のファインチューニングとの主な違いは次のとおりである: (i) T5 の入力にはタスク記述が含まれる; (ii) T5 は Transformer デコーダにより 任意長の系列を生成できる; (iii) 追加層は不要である。

図 11.9.4 テキスト要約のための T5 のファインチューニング。タスク記述と記事トークンの両方が Transformer エンコーダに入力され、要約を予測する。¶
図 11.9.4 は、テキスト要約を例として T5 のファインチューニングを説明している。 この下流タスクでは、 タスク記述トークン “Summarize”, “:” に続いて記事トークンがエンコーダに入力される。
ファインチューニング後、110 億パラメータの T5(T5-11B)は、 複数のエンコーディング(たとえば分類)および生成(たとえば要約)ベンチマークで最先端の結果を達成した。 公開以来、T5 は後続研究で広く利用されている。 たとえば、Switch Transformer は T5 を基に設計され、 パラメータの一部のみを活性化して 計算効率を高めている (Fedus et al., 2022)。 Imagen と呼ばれる text-to-image モデルでは、 テキストは 46 億パラメータを持つ凍結された T5 エンコーダ(T5-XXL)に入力される (Saharia et al., 2022)。 図 11.9.5 の写実的な text-to-image 例は、 T5 エンコーダ単体でも、ファインチューニングなしで テキストを効果的に表現できる可能性を示唆している。

図 11.9.5 Imagen モデルによる text-to-image の例。テキストエンコーダは T5 由来である(図は Saharia et al. (2022) より)。¶
11.9.3. デコーダのみ¶
ここまでで、エンコーダのみおよびエンコーダ–デコーダ Transformer を概観した。 これに対して、デコーダのみ Transformer は、 図 11.7.1 に示した元のエンコーダ–デコーダアーキテクチャから、 エンコーダ全体と、エンコーダ–デコーダのクロスアテンションを含む デコーダのサブレイヤを取り除きる。 今日では、デコーダのみ Transformer は、 自己教師あり学習を通じて世界中に豊富に存在する未ラベルテキストコーパスを活用する 大規模言語モデリング (9.3 章) における 事実上の アーキテクチャとなっている。
11.9.3.1. GPT と GPT-2¶
学習目的として言語モデリングを用い、 GPT (generative pre-training) モデルは Transformer デコーダをそのバックボーンとして選んだ (Radford et al., 2018)。

図 11.9.6 左: 言語モデリングによる GPT の事前学習。ターゲット系列は入力系列を 1 トークンずらしたもの。 “<bos>” と “<eos>” はそれぞれ系列の開始と終了を示す特別なトークンである。右: Transformer デコーダにおける注意パターン。縦軸上の各トークンは、横軸上の過去のトークンのみに注意を向ける(因果的)。¶
9.3.3 章 で説明した自己回帰言語モデルの学習に従い、 図 11.9.6 は Transformer エンコーダを用いた GPT の事前学習を示しており、 ターゲット系列は入力系列を 1 トークンずらしたものである。 Transformer デコーダの注意パターンは、 各トークンが過去のトークンにのみ注意を向けられることを 強制することに注意されたい (未来のトークンはまだ選ばれていないため、注意を向けることができない)。
GPT は 1 億パラメータを持ち、 個々の下流タスクごとにファインチューニングが必要である。 はるかに大規模な Transformer デコーダ言語モデル GPT-2 は、 1 年後に導入された (Radford et al., 2019)。 GPT の元の Transformer デコーダと比べて、事前正規化 (11.8.3 章 で議論) と、 改善された初期化および重みスケーリングが GPT-2 では採用された。 400 GB のテキストで事前学習された 15 億パラメータの GPT-2 は、 言語モデリングベンチマークで最先端の結果を得るとともに、 パラメータやアーキテクチャを更新せずに 複数の他タスクでも有望な結果を示した。
11.9.3.2. GPT-3 とその先¶
GPT-2 は、モデルを更新せずに同じ言語モデルを複数のタスクに使う可能性を示した。 これは、勾配計算によるモデル更新を必要とするファインチューニングよりも、 計算効率が高い。

図 11.9.7 言語モデル(Transformer デコーダ)を用いたゼロショット、ワンショット、フューショットの in-context learning。パラメータ更新は不要である。¶
パラメータ更新なしで言語モデルをより計算効率よく使う方法を説明する前に、 9.5 章 を思い出してほしい。そこでは、言語モデルは ある接頭辞テキスト系列を条件としてテキスト系列を生成するよう学習できる。 したがって、事前学習済み言語モデルは、 タスク記述、タスク固有の入力–出力例、およびプロンプト(タスク入力)を含む入力系列を条件として、 パラメータ更新なし でタスク出力を系列として生成できる。 この学習パラダイムは in-context learning と呼ばれ (Brown et al., 2020)、 タスク固有の入力–出力例がない場合、1 つある場合、少数ある場合に応じて、 ゼロショット、ワンショット、フューショット にさらに分類できる (図 11.9.7)。
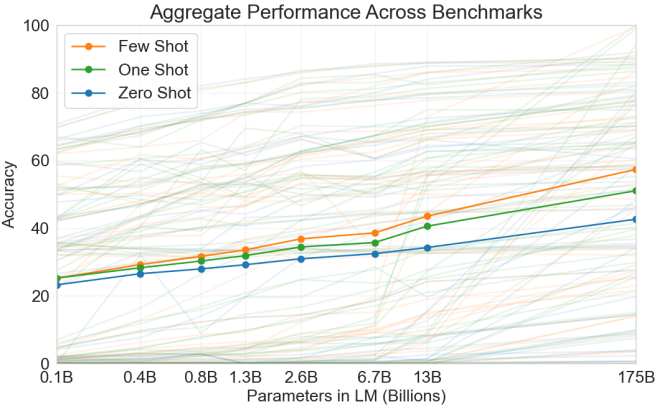
図 11.9.8 GPT-3 の全 42 個の精度指標ベンチマークにおける集計性能(キャプションを調整し、図は Brown et al. (2020) より)。¶
これら 3 つの設定は GPT-3 (Brown et al., 2020) で検証され、 その最大版は GPT-2 の約 2 桁大きいデータとモデルサイズを使用している。 GPT-3 は GPT-2 の直接の後継である GPT-2 と同じ Transformer デコーダアーキテクチャを使用しているが、 注意パターン (図 11.9.6 の右側) は交互の層でより疎になっている。 3000 億トークンで事前学習された GPT-3 は、 より大きなモデルサイズでより良い性能を示し、 フューショット性能が最も急速に向上する (図 11.9.8)。
その後の GPT-4 モデルは、報告書で技術的詳細を完全には公開しなかった (OpenAI, 2023)。 先行モデルとは対照的に、GPT-4 は大規模なマルチモーダルモデルであり、 テキストと画像の両方を入力として受け取り、 テキスト出力を生成できる。
11.9.4. スケーラビリティ¶
図 11.9.8 は、GPT-3 言語モデルにおける Transformer のスケーラビリティを実証的に示している。 言語モデリングに関しては、Transformer のスケーラビリティに関するより包括的な実証研究により、 研究者たちは、より多くのデータと計算量でより大きな Transformer を学習することに可能性を見いだした (Kaplan et al., 2020)。
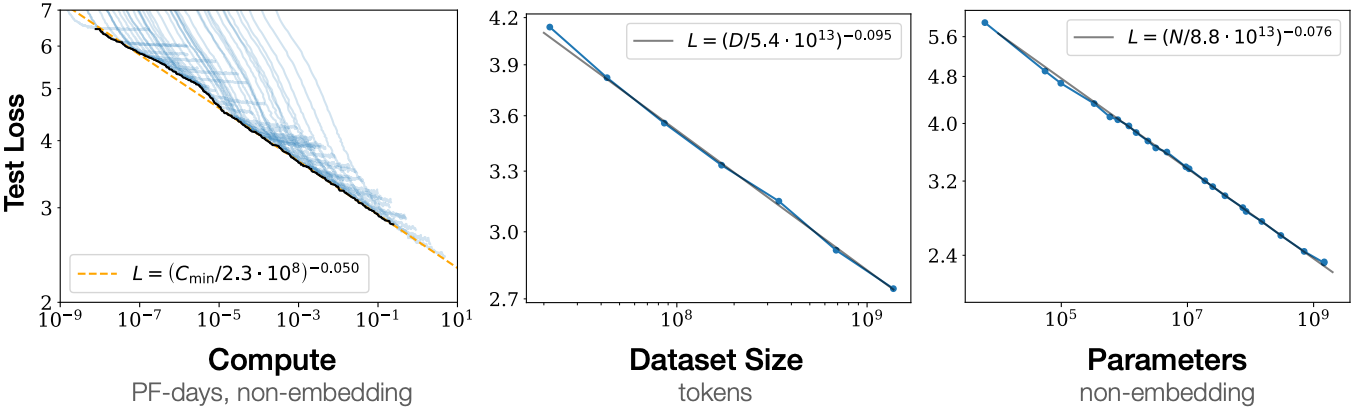
図 11.9.9 Transformer 言語モデルの性能は、モデルサイズ、データセットサイズ、学習に使う計算量を増やすにつれて滑らかに向上する。最適性能を得るには、これら 3 つの要因を同時に拡大する必要がある。実証性能は、他の 2 つにボトルネックされていない場合、各要因それぞれに対してべき乗則の関係を持つ(キャプションを調整し、図は Kaplan et al. (2020) より)。¶
図 11.9.9 に示すように、 べき乗則スケーリング は、モデルサイズ(埋め込み層を除くパラメータ数)、 データセットサイズ(学習トークン数)、 および学習計算量(PetaFLOP/s-days、埋め込み層を除く)に関して 性能に観測される。 一般に、これら 3 つの要因を同時に増やすと、より良い性能につながる。 しかし、それらを どのように 同時に増やすべきかは、 依然として議論の的である (Hoffmann et al., 2022)。
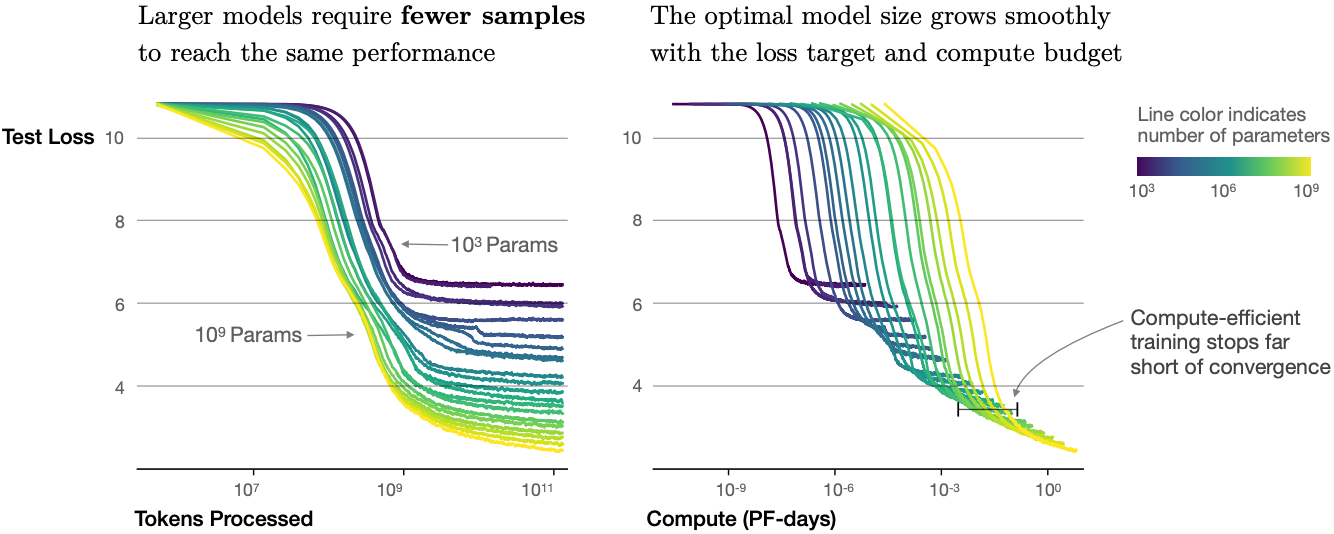
図 11.9.10 Transformer 言語モデルの学習ラン(図は Kaplan et al. (2020) より)。¶
性能向上だけでなく、大規模モデルは小規模モデルよりもサンプル効率にも優れている。 図 11.9.10 は、大規模モデルが小規模モデルと同じ性能を達成するために必要な学習サンプル(処理トークン数)が少なく、性能が計算量に対して滑らかにスケールすることを示している。
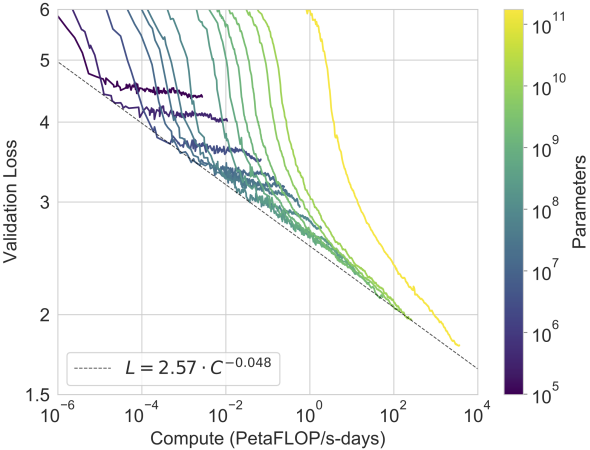
図 11.9.11 GPT-3 の性能(クロスエントロピー検証損失)は、学習に使う計算量に対してべき乗則の傾向に従う。Kaplan et al. (2020) で観測されたべき乗則挙動は、予測曲線からの小さなずれのみで、さらに 2 桁の範囲にわたって続いている。埋め込みパラメータは計算量とパラメータ数から除外されている(キャプションを調整し、図は Brown et al. (2020) より)。¶
(Kaplan et al., 2020) における実証的スケーリング挙動は、その後の大規模 Transformer モデルでも検証されている。たとえば、GPT-3 は 図 11.9.11 において、さらに 2 桁の範囲でこの仮説を支持した。
11.9.5. 大規模言語モデル¶
GPT 系列における Transformer のスケーラビリティは、その後の大規模言語モデルに影響を与えた。 GPT-2 の Transformer デコーダは、2700 億トークンで学習された 5300 億パラメータの Megatron-Turing NLG の学習に用いられた (Smith et al., 2022)。GPT-2 の設計に従い、2800 億パラメータの Gopher (Rae et al., 2021) は 3000 億トークンで事前学習され、多様なタスクで競争力のある性能を示した。 同じアーキテクチャを継承し、Gopher と同じ計算予算を用いた Chinchilla (Hoffmann et al., 2022) は、はるかに小さい(700 億パラメータ)モデルでありながら、より長く学習(1.4 兆トークン)し、多くのタスクで Gopher を上回り、パラメータ数よりもトークン数を重視する結果となった。 言語モデリングのスケーリングの流れを継続するために、 PaLM (Pathway Language Model) (Chowdhery et al., 2022) は、修正された設計を持つ 5400 億パラメータの Transformer デコーダで、7800 億トークンで事前学習され、BIG-Bench ベンチマークにおいて平均的な人間性能を上回った (Srivastava et al., 2022)。その後継である PaLM 2 (Anil et al., 2023) は、データとモデルをおおむね 1:1 で拡大し、多言語能力と推論能力を向上させた。 Minerva (Lewkowycz et al., 2022) のように汎用モデル(PaLM)をさらに学習したものや、一般コーパスで学習されていない Galactica (Taylor et al., 2022) などの他の大規模言語モデルも、有望な定量的推論能力および科学的推論能力を示した。
OPT (Open Pretrained Transformers) (Zhang et al., 2022)、BLOOM (Scao et al., 2022)、FALCON (Penedo et al., 2023) のようなオープンソース公開は、 大規模言語モデルの研究と利用を民主化した。 推論時の計算効率に焦点を当てたオープンソースの Llama 1 (Touvron et al., 2023a) は、通常よりも多くのトークンで学習することで、はるかに大きなモデルを上回った。更新版の Llama 2 (Touvron et al., 2023b) は事前学習コーパスをさらに 40% 増やし、競合するクローズドソースモデルに匹敵しうる製品モデルにつながった。
Wei et al. (2022) は、大規模モデルには存在するが小規模モデルには存在しない、大規模言語モデルの創発的能力について議論した。 しかし、単にモデルサイズを大きくするだけでは、モデルが人間の指示によりよく従うようになるわけではない。 Sanh et al. (2021), Wei et al. (2021) は、指示 によって記述されたさまざまなデータセットで大規模言語モデルをファインチューニングすると、 保持されたタスクに対するゼロショット性能が向上することを見いだした。 人間のフィードバックからの強化学習 を用いて、 Ouyang et al. (2022) は GPT-3 をファインチューニングし、 多様な指示に従えるようにした。 その結果として得られた InstructGPT に続き、 ファインチューニングを通じて言語モデルを人間の意図に整合させる (Ouyang et al., 2022) ChatGPT は、人間のような応答(たとえばコードのデバッグや創作的な文章作成)を 人間との会話に基づいて生成でき、 多くの自然言語処理タスクをゼロショットで実行できる (Qin et al., 2023)。 Bai et al. (2022) は、指示チューニングの過程を部分的に自動化するために、人間の入力(たとえば人手ラベル付きデータ)をモデル出力で置き換えた。 AI フィードバックからの強化学習 とも呼ばれる。
大規模言語モデルは、プロンプト とも呼ばれる in-context learning を通じて、 望ましいタスクをモデルに実行させるためのテキスト入力の与え方を定式化する、刺激的な可能性を提供する。 特に、 chain-of-thought prompting (Wei et al., 2022) は、 少数ショットの「質問、中間推論ステップ、答え」のデモンストレーションを用いる in-context learning 手法であり、 大規模言語モデルの複雑な推論能力を引き出して、 数学、常識、記号推論のタスクを解くのに役立つ。 複数の推論経路をサンプリングすること (Wang et al., 2023)、少数ショットのデモンストレーションを多様化すること (Zhang et al., 2023)、 複雑な問題を部分問題に分解すること (Zhou et al., 2023) は、いずれも推論精度を改善できる。実際、各答えの直前に “Let’s think step by step” のような単純なプロンプトを与えるだけで、 大規模言語モデルは十分な精度で ゼロショット の chain-of-thought 推論さえ実行できる (Kojima et al., 2022)。 テキストと画像の両方からなるマルチモーダル入力に対しても、 言語モデルはテキスト入力のみを用いる場合より高い精度でマルチモーダル chain-of-thought 推論を実行できる (Zhang et al., 2023)。
11.9.6. 要約と考察¶
Transformer は、エンコーダのみ(たとえば BERT)、エンコーダ–デコーダ(たとえば T5)、およびデコーダのみ(たとえば GPT 系列)として事前学習されてきた。事前学習済みモデルは、モデル更新あり(たとえばファインチューニング)またはなし(たとえばフューショット)で、さまざまなタスクに適応できる。Transformer のスケーラビリティは、より大きなモデル、より多くの学習データ、より多くの学習計算量がより良い性能につながることを示唆している。Transformer はもともとテキストデータ向けに設計・事前学習されたため、この節はやや自然言語処理に寄っている。それでも、上で議論したこれらのモデルは、より最近の複数モダリティにまたがるモデルでもしばしば見られる。たとえば、 (i) Chinchilla (Hoffmann et al., 2022) はさらに Flamingo (Alayrac et al., 2022) に拡張され、フューショット学習のための視覚言語モデルとなった; (ii) GPT-2 (Radford et al., 2019) と Vision Transformer は、CLIP (Contrastive Language-Image Pre-training) (Radford et al., 2021) においてテキストと画像をエンコードし、その画像埋め込みとテキスト埋め込みは後に DALL-E 2 の text-to-image システム (Ramesh et al., 2022) に採用された。マルチモーダル事前学習における Transformer のスケーラビリティについてはまだ体系的研究がないが、Parti (Yu et al., 2022) と呼ばれる全 Transformer の text-to-image モデルは、モダリティをまたいだスケーラビリティの可能性を示している: より大きな Parti は、より高忠実度な画像生成と、内容豊かなテキスト理解が可能である (図 11.9.12)。

図 11.9.12 同じテキストから生成された、サイズが増加する Parti モデル(350M、750M、3B、20B)による画像例(例は Yu et al. (2022) より)。¶
11.9.7. 演習¶
異なるタスクからなるミニバッチを用いて T5 をファインチューニングすることは可能か? なぜか、なぜではないか? GPT-2 ではどうだろうか。
強力な言語モデルがあるとしたら、どのような応用が考えられるか?
追加層を加えて言語モデルをテキスト分類にファインチューニングするよう求められたとする。どこにそれらを追加するか? なぜか?
ターゲット系列の予測全体を通して入力系列が常に利用可能な系列変換問題(たとえば機械翻訳)を考えよ。デコーダのみ Transformer でモデル化することの限界は何だろうか。 なぜか?