4.7. 環境と分布シフト¶
前の節では、 機械学習のさまざまな実践的応用を通して、 多様なデータセットにモデルを当てはめてきた。 しかし、そもそもデータがどこから来たのか、 あるいはモデルの出力を最終的に何に使うのか、 という点について立ち止まって考えることはなかった。 データを手にした機械学習開発者は、 こうした根本的な問題を考えずに モデル開発へと急ぎがちである。
失敗した機械学習の導入の多くは、 この見落としに起因している。 テストセット精度で見ると非常に優秀に見えるのに、 本番導入するとデータ分布が突然変化して 壊滅的に失敗することがある。 さらに厄介なのは、モデルの導入そのものが データ分布を乱す引き金になる場合があることである。 たとえば、ある人がローンを返済するか延滞するかを予測するモデルを学習し、 申請者の履物の選択が延滞リスクと関連している (オックスフォード靴は返済、スニーカーは延滞)と分かったとする。 すると、 オックスフォード靴を履いている申請者にはローンを認め、 スニーカーを履いている申請者はすべて拒否したくなるかもしれない。
この場合、パターン認識から意思決定への 軽率な飛躍と、環境を批判的に考慮しない姿勢が、 悲惨な結果を招く可能性がある。 まず、履物に基づいて判断し始めた瞬間に、 顧客はそのことに気づいて行動を変えるだろう。 やがて、信用力が改善したわけでもないのに、 すべての申請者がオックスフォード靴を履くようになるはずである。 少し立ち止まって考えてみよ。 機械学習の多くの応用で同様の問題が起こりうるからである。 モデルに基づく意思決定を環境に持ち込むことで、 モデルそのものを壊してしまうかもしれないのである。
この節だけでこれらの話題を完全に扱うことはできないが、 ここではよくある懸念をいくつか示し、 そのような状況を早期に検知し、 被害を軽減し、 機械学習を責任ある形で使うために必要な 批判的思考を促したいと思う。 解決策の中には単純なものもある (「正しい」データを求めること)、 技術的に難しいものもある (強化学習システムを実装すること)、 また、統計的予測の領域を超えて、 アルゴリズムの倫理的な適用に関する 難しい哲学的問題に取り組む必要があるものもある。
4.7.1. 分布シフトの種類¶
まずは受動的な予測設定に立ち返り、 データ分布がどのように変化しうるか、 そしてモデル性能を救うために何ができるかを考える。 古典的な設定の一つでは、訓練データが ある分布 \(p_S(\mathbf{x},y)\) からサンプリングされた一方で、 テストデータは 別の分布 \(p_T(\mathbf{x},y)\) から得られる ラベルなしのデータ例で構成されると仮定する。 この時点で、厳しい現実に向き合わなければならない。 \(p_S\) と \(p_T\) の関係について 何の仮定も置かないなら、 頑健な分類器を学習することは不可能である。
犬と猫を区別したい二値分類問題を考えよう。 分布が任意の形で変化しうるなら、 入力分布は一定のまま \(p_S(\mathbf{x}) = p_T(\mathbf{x})\) である一方、 ラベルだけがすべて反転するという病的なケースを 許してしまいます: \(p_S(y \mid \mathbf{x}) = 1 - p_T(y \mid \mathbf{x})\)。 言い換えると、神が突然、 将来はすべての「猫」が犬であり、 以前「犬」と呼んでいたものが猫であると決めたとしても―― 入力分布 \(p(\mathbf{x})\) に何の変化もないまま―― この状況を、分布がまったく変わらなかった場合と 区別することはできない。
幸いなことに、将来データがどのように変化しうるかについて いくつかの制約付き仮定を置けば、 原理に基づくアルゴリズムがシフトを検知し、 場合によってはその場で適応して、 元の分類器の精度を上回ることさえできる。
4.7.1.1. 共変量シフト¶
分布シフトのカテゴリの中でも、 共変量シフトは最も広く研究されているものかもしれない。 ここでは、入力分布は時間とともに変化しうるが、 ラベル付け関数、すなわち条件付き分布 \(P(y \mid \mathbf{x})\) は変化しないと仮定する。 統計学では、共変量(特徴量)の分布が変化することから この問題を covariate shift と呼ぶ。 因果性を持ち出さずに分布シフトを論じることもできるが、 \(\mathbf{x}\) が \(y\) を引き起こすと考える状況では、 共変量シフトは自然な仮定である。
猫と犬を見分ける課題を考えてみよう。 訓練データは 図 4.7.1 のような画像で構成されているかもしれない。

図 4.7.1 猫と犬を区別するための訓練データ(イラスト: Lafeez Hossain / 500px / Getty Images; ilkermetinkursova / iStock / Getty Images Plus; GlobalP / iStock / Getty Images Plus; Musthafa Aboobakuru / 500px / Getty Images)。¶
テスト時には 図 4.7.2 の画像を分類するよう求められる。

図 4.7.2 猫と犬を区別するためのテストデータ(イラスト: SIBAS_minich / iStock / Getty Images Plus; Ghrzuzudu / iStock / Getty Images Plus; id-work / DigitalVision Vectors / Getty Images; Yime / iStock / Getty Images Plus)。¶
訓練セットは写真で構成されているのに対し、 テストセットには漫画しか含まれていない。 テストセットと大きく異なる特徴を持つデータセットで学習すると、 新しいドメインにどう適応するかという一貫した計画がない限り、 問題を引き起こす。
4.7.1.2. ラベルシフト¶
ラベルシフト はその逆の問題を表す。 ここでは、ラベルの周辺分布 \(P(y)\) は変化しうるが、 クラス条件付き分布 \(P(\mathbf{x} \mid y)\) は ドメイン間で固定されていると仮定する。 ラベルシフトは、\(y\) が \(\mathbf{x}\) を引き起こすと考えるときに 妥当な仮定である。 たとえば、診断名の相対的な有病率が時間とともに変化していても、 症状(あるいは他の現れ方)から診断を予測したい場合がある。 ここでは病気が症状を引き起こすので、 ラベルシフトの仮定が適切である。 退化的な場合には、ラベルシフトと共変量シフトの仮定が 同時に成り立つこともある。 たとえばラベルが決定論的であれば、 たとえ \(y\) が \(\mathbf{x}\) を引き起こす場合でも、 共変量シフトの仮定は満たされる。 興味深いことに、このような場合には、 ラベルシフトの仮定から導かれる手法を使う方が 有利なことが多い。 その理由は、これらの手法が 入力のように見える高次元の対象ではなく、 ラベルのように見える対象(しばしば低次元)を 操作することが多いからである。 深層学習では入力は画像のような高次元オブジェクトになりがちであるが、 ラベルはカテゴリのようなより単純なオブジェクトであることが多いのである。
4.7.1.3. 概念シフト¶
関連する問題として concept shift もある。 これは、ラベルの定義そのものが変わりうるときに生じる。 妙に聞こえるかもしれない――猫 は 猫 だろう? しかし、他のカテゴリでは時間とともに用法が変化する。 精神疾患の診断基準、何が流行と見なされるか、職名などは、 いずれもかなりの概念シフトの影響を受ける。 実際、米国を地理的に移動してデータの収集元を変えると、 図 4.7.3 に示すように、 炭酸飲料 の呼び名の分布にかなりの概念シフトが見られる。
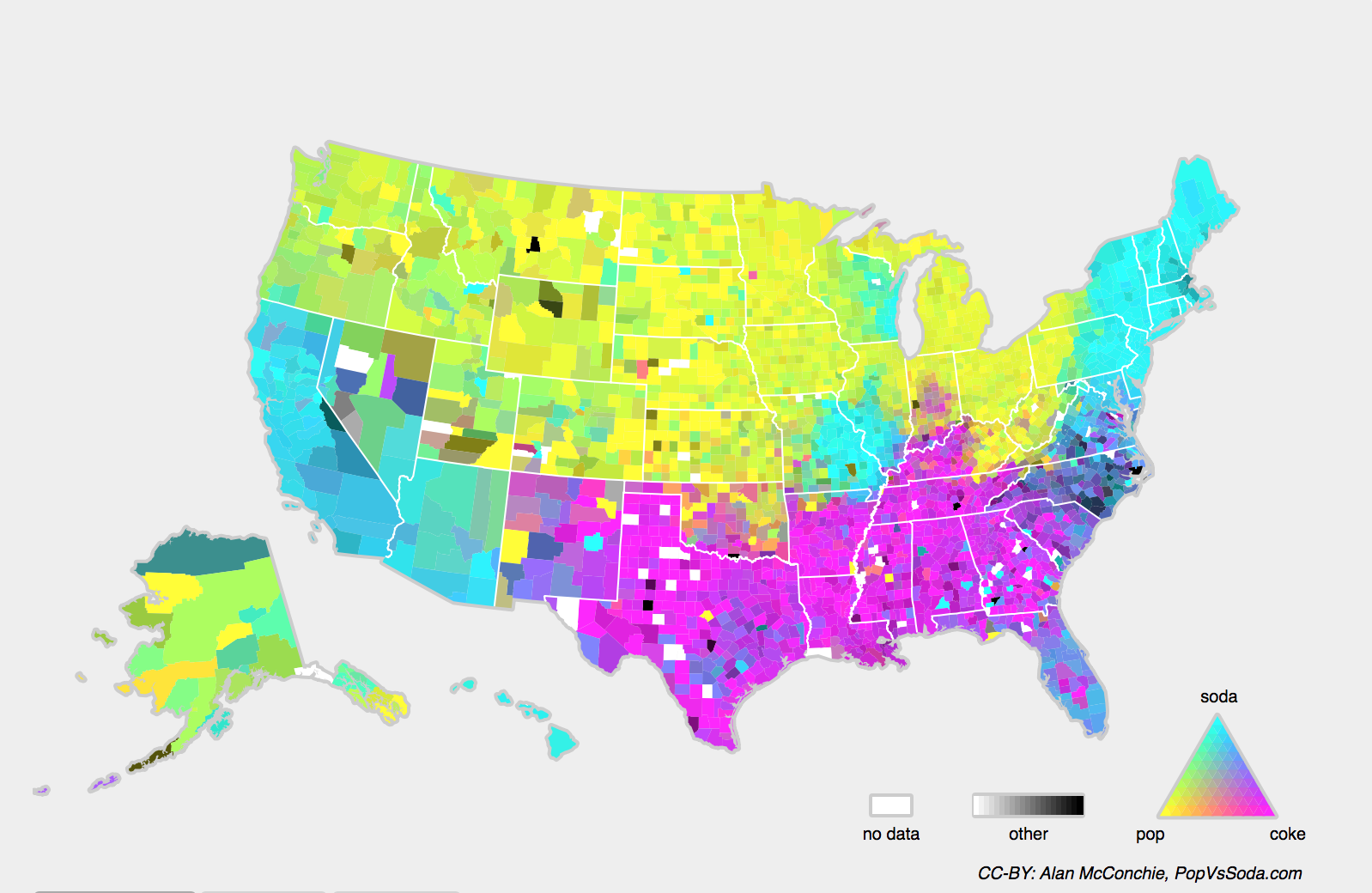
図 4.7.3 米国における炭酸飲料名の概念シフト(CC-BY: Alan McConchie, PopVsSoda.com)。¶
機械翻訳システムを構築する場合、 \(P(y \mid \mathbf{x})\) の分布は場所によって異なるかもしれない。 この問題は見つけるのが難しいことがある。 時間的あるいは地理的な意味で、 シフトが徐々にしか起こらないという知識を活用できると期待したくなる。
4.7.2. 分布シフトの例¶
形式論やアルゴリズムに入る前に、 共変量シフトや概念シフトが 一見して明らかでない具体例をいくつか見てみよう。
4.7.2.1. 医療診断¶
がんを検出するアルゴリズムを設計したいとしよう。 健康な人と病気の人からデータを集めて、 アルゴリズムを学習する。 うまく動き、高い精度が得られたので、 医療診断で成功するキャリアの準備ができたと結論づける。 そう簡単ではない。
訓練データを生み出した分布と、 実運用で遭遇する分布はかなり異なるかもしれない。 これは、何年も前に著者の何人かが関わった ある不運なスタートアップでも起こった。 主に高齢男性に影響する病気の血液検査を開発しており、 患者から採取した血液サンプルを使って研究したいと考えていた。 しかし、すでにシステムに入っている病気の患者からよりも、 健康な男性から血液サンプルを得る方がはるかに難しいのである。 そこでそのスタートアップは、 大学キャンパスの学生から血液提供を募り、 検査開発における健康対照群として使った。 その後、私たちにその病気を検出する分類器の構築を 手伝ってもらえないかと依頼してきた。
私たちが説明したように、 健康群と病気群をほぼ完全な精度で 見分けること自体は確かに簡単である。 しかし、被験者が 年齢、ホルモンレベル、身体活動、食事、飲酒量、 そして病気とは無関係な多くの要因で異なっていたからである。 実際の患者ではそのようなことはまずない。 このサンプリング手順のために、 極端な共変量シフトが起こると予想された。 さらに、このケースは 従来の方法では修正できない可能性が高かったのである。 要するに、かなりの金額を無駄にした。
4.7.2.2. 自動運転車¶
ある会社が機械学習を活用して 自動運転車を開発したいと考えたとする。 ここで重要な構成要素の一つが路肩検出器である。 実際の注釈付きデータは高価なので、 ゲームのレンダリングエンジンから得た合成データを 追加の訓練データとして使うという (賢くもあり、疑わしくもある)アイデアを思いついた。 レンダリングエンジンから得た「テストデータ」では 非常によく機能した。 ところが、実車では大失敗でした。 調べてみると、路肩は非常に単純なテクスチャで レンダリングされていたのである。 さらに重要なのは、路肩のすべてが 同じテクスチャでレンダリングされており、 路肩検出器はこの「特徴」をすぐに学習してしまったことである。
同様のことは、米軍が森林内の戦車検出を試みたときにも起こった。 戦車のない森林の航空写真を撮り、 その後戦車を森林に持ち込んで 別の写真を撮った。 分類器は完璧に動作しているように見えた。 しかし実際には、木と影のある木を 区別する方法を学んだだけだったのである―― 最初の写真は早朝に、2回目の写真は正午に撮影されていた。
4.7.2.3. 非定常分布¶
より微妙な状況は、 分布がゆっくり変化する場合 (非定常分布 とも呼ばれます)で、 モデルが十分に更新されないときに生じる。 典型的な例をいくつか挙げる。
計算広告モデルを学習したのに、頻繁に更新しない(たとえば、iPad という新しい目立たないデバイスが発売されたことを取り込むのを忘れる)。
スパムフィルタを作る。これまで見たすべてのスパムの検出にはうまくいく。しかし、スパマーが賢くなり、これまで見たことのないような新しいメッセージを作る。
商品推薦システムを作る。冬の間はうまく動くが、クリスマスが過ぎてもサンタ帽を推薦し続ける。
4.7.2.4. さらにいくつかの逸話¶
顔検出器を作る。すべてのベンチマークではうまくいく。ところがテストデータでは失敗する――問題の例は顔が画像全体を占めるクローズアップである(訓練セットにはそのようなデータがなかった)。
米国市場向けのウェブ検索エンジンを作り、それを英国で展開したい。
大規模なデータセットをまとめて画像分類器を学習する。クラス数が非常に多く、たとえば1000カテゴリがそれぞれ1000枚ずつで均等に表現されているデータセットを作る。その後、実世界にシステムを導入すると、写真の実際のラベル分布は明らかに一様ではない。
4.7.3. 分布シフトの補正¶
すでに述べたように、訓練分布とテスト分布 \(P(\mathbf{x}, y)\) が異なる場合は多くある。 場合によっては、共変量シフト、ラベルシフト、概念シフトがあっても モデルがうまく動く幸運に恵まれる。 別の場合には、シフトに対処するための原理に基づく戦略を用いることで、 より良い結果を得られる。 この節の残りはかなり技術的になる。 せっかちな読者は次節へ進んでも構わない。 ここでの内容は後続の概念の前提ではないからである。
4.7.3.1. 経験リスクとリスク¶
まず、モデル訓練中に実際に何が起きているのかを 振り返ってみよう。 訓練データ \(\{(\mathbf{x}_1, y_1), \ldots, (\mathbf{x}_n, y_n)\}\) の特徴量と対応するラベルを順に見て、 ミニバッチごとにモデル \(f\) のパラメータを更新する。 簡単のため正則化は考えず、 主として訓練データ上の損失を最小化する:
ここで \(l\) は、対応するラベル \(y_i\) が与えられたときの予測 \(f(\mathbf{x}_i)\) が 「どれだけ悪いか」を測る損失関数である。 統計学では (4.7.1) の項を 経験リスク と呼ぶ。 経験リスク は、真の分布 \(p(\mathbf{x},y)\) から得られるデータ全体にわたる 損失の期待値である リスク を近似するための、 訓練データ上の平均損失である:
しかし実際には、通常データ全体を入手することはできない。 したがって、経験リスク最小化、 すなわち (4.7.1) の経験リスクを最小化することは、 リスクを近似的に最小化することを期待した 機械学習の実践的戦略である。
4.7.3.2. 共変量シフトの補正¶
ラベル付きデータ \((\mathbf{x}_i, y_i)\) があり、 ある依存関係 \(P(y \mid \mathbf{x})\) を推定したいとする。 残念ながら、観測 \(\mathbf{x}_i\) は ソース分布 \(q(\mathbf{x})\) から得られており、 ターゲット分布 \(p(\mathbf{x})\) からではない。 幸いなことに、 依存関係の仮定により条件付き分布は変化しないので、 \(p(y \mid \mathbf{x}) = q(y \mid \mathbf{x})\) である。 ソース分布 \(q(\mathbf{x})\) が「間違っている」なら、 リスクにおける次の単純な恒等式を使って補正できる:
言い換えると、各データ例を、 正しい分布からサンプリングされる確率と 誤った分布からサンプリングされる確率の比で 再重み付けする必要がある:
各データ例 \((\mathbf{x}_i, y_i)\) に重み \(\beta_i\) を代入すれば、 重み付き経験リスク最小化 を用いてモデルを学習できる:
残念ながら、この比は分からない。 したがって、何か有用なことをする前に、 それを推定する必要がある。 さまざまな方法が利用可能であり、 最小ノルム原理や最大エントロピー原理を用いて 期待演算子そのものを再較正しようとする 洗練された作用素論的アプローチもある。 このような手法では、 両方の分布からサンプルが必要であることに注意されたい―― 「真の」 \(p\)、たとえばテストデータへのアクセス、 および訓練セット生成に使った \(q\)(後者は自明に利用可能)である。 ただし、必要なのは特徴量 \(\mathbf{x} \sim p(\mathbf{x})\) だけであり、 ラベル \(y \sim p(y)\) にアクセスする必要はない。
この場合、元の方法とほぼ同等の結果を与える 非常に効果的なアプローチがある。 ロジスティック回帰である。 二値分類におけるソフトマックス回帰の特殊例である(4.1 章 を参照)。 これだけで推定確率比を計算できる。 これは、\(p(\mathbf{x})\) から得られたデータと \(q(\mathbf{x})\) から得られたデータを区別する分類器を学習する。 もし2つの分布を区別できないなら、 対応するインスタンスが どちらの分布から来たとしても 同じくらい起こりやすいことを意味する。 一方、うまく識別できるインスタンスは、 それに応じて大きく重み付けまたは小さく重み付けすべきである。
簡単のため、両方の分布 \(p(\mathbf{x})\) と \(q(\mathbf{x})\) からのインスタンス数が等しいと仮定する。 ここで、\(z\) を \(p\) から得られたデータには1、 \(q\) から得られたデータには-1のラベルとする。 すると、混合データセットにおける確率は
したがって、ロジスティック回帰アプローチを使い、 \(P(z=1 \mid \mathbf{x})=\frac{1}{1+\exp(-h(\mathbf{x}))}\)(\(h\) はパラメータ化された関数)とすると、 次が成り立ちる。
その結果、2つの問題を解く必要がある。 1つ目は、両方の分布から得られたデータを区別すること、 2つ目は、(4.7.5) における 重み \(\beta_i\) を用いた重み付き経験リスク最小化問題である。
これで補正アルゴリズムを説明する準備が整った。 訓練セット \(\{(\mathbf{x}_1, y_1), \ldots, (\mathbf{x}_n, y_n)\}\) と ラベルなしテストセット \(\{\mathbf{u}_1, \ldots, \mathbf{u}_m\}\) があるとする。 共変量シフトでは、 すべての \(1 \leq i \leq n\) に対する \(\mathbf{x}_i\) は あるソース分布から得られ、 すべての \(1 \leq i \leq m\) に対する \(\mathbf{u}_i\) は ターゲット分布から得られると仮定する。 共変量シフトを補正する典型的なアルゴリズムは次のとおりである。
二値分類の訓練セットを作る:\(\{(\mathbf{x}_1, -1), \ldots, (\mathbf{x}_n, -1), (\mathbf{u}_1, 1), \ldots, (\mathbf{u}_m, 1)\}\)。
ロジスティック回帰を用いて二値分類器を学習し、関数 \(h\) を得る。
訓練データを \(\beta_i = \exp(h(\mathbf{x}_i))\)、あるいはより良くは定数 \(c\) に対して \(\beta_i = \min(\exp(h(\mathbf{x}_i)), c)\) で重み付けする。
(4.7.5) において、\(\{(\mathbf{x}_1, y_1), \ldots, (\mathbf{x}_n, y_n)\}\) で学習する際に重み \(\beta_i\) を使う。
上のアルゴリズムは重要な仮定に依存していることに注意されたい。 この方式が機能するには、ターゲット(たとえばテスト時)の分布における各データ例が、 訓練時に発生する非ゼロ確率を持っていなければならない。 もし \(p(\mathbf{x}) > 0\) だが \(q(\mathbf{x}) = 0\) となる点があれば、 対応する重要度重みは無限大になるはずである。
4.7.3.3. ラベルシフトの補正¶
\(k\) 個のカテゴリを持つ分類タスクを扱っているとする。 4.7.3.2 章 と同じ記法を用い、 \(q\) と \(p\) はそれぞれソース分布(たとえば訓練時)と ターゲット分布(たとえばテスト時)である。 ラベルの分布が時間とともに変化し、 \(q(y) \neq p(y)\) だが、クラス条件付き分布は \(q(\mathbf{x} \mid y)=p(\mathbf{x} \mid y)\) として同じままだと仮定する。 ソース分布 \(q(y)\) が「間違っている」なら、 (4.7.2) で定義されたリスクにおける 次の恒等式に従って補正できる:
ここでの重要度重みは、 ラベルの尤度比に対応する:
ラベルシフトのよい点の一つは、 ソース分布上でそこそこ良いモデルがあれば、 周囲次元を扱うことなく これらの重みを一貫して推定できることである。 深層学習では、入力は画像のような高次元オブジェクトになりがちであるが、 ラベルはカテゴリのようなより単純なオブジェクトであることが多い。
ターゲットのラベル分布を推定するには、 まず、そこそこ良い既製の分類器 (通常は訓練データで学習されたもの)を取り、 検証セット(これも訓練分布から得られる)を使って その「混同行列」を計算する。 混同行列 \(\mathbf{C}\) は単なる \(k \times k\) 行列で、 各列がラベルカテゴリ(正解)に対応し、 各行がモデルの予測カテゴリに対応する。 各セルの値 \(c_{ij}\) は、 検証セット上の全予測のうち、 真のラベルが \(j\) でモデルが \(i\) を予測した割合である。
しかし、ターゲットデータ上で混同行列を直接計算することはできない。 なぜなら、実運用で目にするデータ例のラベルは見えないからである。 複雑なリアルタイム注釈パイプラインに投資しない限りはそうである。 ただし、できることは、 テスト時のモデル予測をすべて平均し、 平均モデル出力 \(\mu(\hat{\mathbf{y}}) \in \mathbb{R}^k\) を得ることである。 ここで \(i^\textrm{th}\) 要素 \(\mu(\hat{y}_i)\) は、 テストセット上の全予測のうち、 モデルが \(i\) を予測した割合である。
いくつかの穏やかな条件の下では―― 分類器が最初からそこそこ正確であり、 ターゲットデータに以前見たことのあるカテゴリしか含まれず、 しかもラベルシフトの仮定が最初から成り立っている(ここではこれが最も強い仮定である)―― 次の単純な線形方程式を解くことで テストセットのラベル分布を推定できる。
なぜなら推定として、すべての \(1 \leq i \leq k\) について \(\sum_{j=1}^k c_{ij} p(y_j) = \mu(\hat{y}_i)\) が成り立つからである。 ここで \(p(y_j)\) は、\(k\) 次元のラベル分布ベクトル \(p(\mathbf{y})\) の \(j^\textrm{th}\) 要素である。 分類器が最初から十分に正確であれば、 混同行列 \(\mathbf{C}\) は可逆となり、 \(p(\mathbf{y}) = \mathbf{C}^{-1} \mu(\hat{\mathbf{y}})\) という解が得られる。
ソースデータではラベルが観測できるので、 分布 \(q(y)\) を推定するのは容易である。 すると、ラベル \(y_i\) を持つ任意の訓練データ例 \(i\) について、 推定した \(p(y_i)/q(y_i)\) の比を取り、 重み \(\beta_i\) を計算し、 (4.7.5) の 重み付き経験リスク最小化に代入できる。
4.7.3.4. 概念シフトの補正¶
概念シフトを原理に基づいて修正するのは、はるかに難しい。 たとえば、突然問題が 猫と犬の区別から白い動物と黒い動物の区別に変わるような状況では、 新しいラベルを集めて ゼロから学習し直す以上に良いことができると仮定するのは 無理がある。 幸い、実際にはそのような極端なシフトはまれである。 むしろ通常は、タスクがゆっくり変化し続ける。 より具体的にするため、いくつか例を挙げる。
計算広告では新製品が発売され、旧製品は人気が下がる。つまり、広告とその人気の分布は徐々に変化し、それに合わせてクリック率予測器も徐々に変化する必要がある。
交通監視カメラのレンズは環境による摩耗で徐々に劣化し、画像品質に段階的に影響する。
ニュースの内容は徐々に変化する(つまり、ほとんどのニュースは変わらないが、新しい話題が現れる)。
このような場合には、データの変化に適応させるためにネットワークを訓練するときと同じアプローチを使える。言い換えると、既存のネットワーク重みを使い、ゼロから訓練するのではなく、新しいデータで数回更新するだけである。
4.7.4. 学習問題の分類¶
分布の変化にどう対処するかを理解したので、 機械学習問題の定式化に関する他の側面も考えてみよう。
4.7.4.1. バッチ学習¶
バッチ学習 では、訓練特徴量とラベル \(\{(\mathbf{x}_1, y_1), \ldots, (\mathbf{x}_n, y_n)\}\) にアクセスでき、それを使ってモデル \(f(\mathbf{x})\) を訓練する。 その後、このモデルを同じ分布から得られた新しいデータ \((\mathbf{x}, y)\) のスコア付けに使う。 ここで述べる問題のデフォルトの仮定はこれである。 たとえば、猫と犬のたくさんの画像に基づいて 猫検出器を訓練するかもしれない。 一度訓練したら、それを 賢い猫ドアのコンピュータビジョンシステムの一部として出荷し、 猫だけを通すようにする。 その後は顧客の家に設置され、 (極端な事情がない限り)二度と更新されない。
4.7.4.2. オンライン学習¶
今度は、データ \((\mathbf{x}_i, y_i)\) が 1サンプルずつ到着すると想像しよう。 より具体的には、まず \(\mathbf{x}_i\) を観測し、 その後で \(f(\mathbf{x}_i)\) の推定値を出す必要があるとする。 これを行って初めて \(y_i\) を観測し、 その決定に応じて報酬を得るか損失を被りる。 多くの現実問題はこのカテゴリに入りる。 たとえば、明日の株価を予測し、 その推定に基づいて取引し、 一日の終わりにその推定が利益を生んだかどうかを知る必要がある。 言い換えると、オンライン学習 では、 新しい観測に応じてモデルを継続的に改善する次のサイクルがある:
4.7.4.3. バンディット¶
バンディット は上の問題の特殊ケースである。 多くの学習問題では、パラメータを学習したい連続的にパラメータ化された関数 \(f\) (たとえば深層ネットワーク)を扱いるが、 バンディット 問題では、引ける腕の数が有限、 すなわち取れる行動の数が有限である。 このより単純な問題では、最適性に関して より強い理論保証が得られるのはそれほど驚くことではない。 ここで取り上げるのは主に、 この問題がしばしば(紛らわしく)別個の学習設定として扱われるからである。
4.7.4.4. 制御¶
多くの場合、環境は私たちが何をしたかを覚えている。 必ずしも敵対的というわけではないが、 単に記憶しており、応答は以前に何が起きたかに依存する。 たとえば、コーヒーボイラーの制御装置は、 以前にボイラーを加熱していたかどうかによって 異なる温度を観測する。 PID(比例・積分・微分)制御アルゴリズムはそこでよく使われる。 同様に、ニュースサイトでのユーザーの行動は、 以前に何を見せたかに依存する (たとえば、多くのニュースは一度しか読まれない)。 このようなアルゴリズムの多くは、 自分が作用する環境のモデルを作り、 意思決定がよりランダムに見えないようにする。 近年では、 制御理論(たとえば PID の変種)が、 より良い分離表現と再構成品質を得るための ハイパーパラメータの自動調整や、 生成テキストの多様性および生成画像の再構成品質の改善にも使われている (Shao et al., 2020)。
4.7.4.5. 強化学習¶
記憶を持つ環境というより一般的な場合には、 環境が私たちと協力しようとする状況 (協力ゲーム、特にゼロ和でないゲーム)や、 逆に環境が勝とうとする状況に出会うかもしれない。 チェス、囲碁、バックギャモン、StarCraft などは 強化学習 の例である。 同様に、自動運転車のための良い制御器を作りたいこともある。 他の車は、自動運転車の運転スタイルに対して 非自明な形で反応する可能性が高く、 たとえば避けようとしたり、事故を起こそうとしたり、 協力しようとしたりする。
4.7.4.6. 環境を考慮する¶
上のさまざまな状況の重要な違いの一つは、 静的な環境では通用した戦略が、 適応可能な環境では通用しないかもしれないことである。 たとえば、トレーダーが見つけた裁定機会は、 一度利用されると消えてしまう可能性が高い。 環境が変化する速度とその仕方が、 私たちが適用できるアルゴリズムの種類を大きく左右する。 たとえば、変化がゆっくりしか起こらないと分かっていれば、 推定値もゆっくりしか変化しないようにできる。 環境が瞬時に変化しうるが、 それが非常にまれだと分かっていれば、 その点を考慮できる。 こうした知識は、解かれている問題が時間とともに変化しうる 概念シフトに対処するうえで、 志あるデータサイエンティストにとって極めて重要である。
4.7.5. 機械学習における公平性、説明責任、透明性¶
最後に、機械学習システムを導入するとき、 単に予測モデルを最適化しているだけではないことを 忘れてはならない――通常は、 意思決定を(部分的または完全に)自動化するために使われる 道具を提供しているのである。 こうした技術システムは、 その結果として下される決定の対象となる個人の生活に 影響を与える。 予測を考えることから意思決定へと飛躍すると、 新しい技術的問題だけでなく、 慎重に検討すべき倫理的問題が 大量に生じる。 医療診断システムを導入するなら、 どの集団に対して有効で、どの集団では有効でないのかを 知る必要がある。 ある集団に対する予見可能なリスクを見落とすと、 劣った医療を提供してしまうかもしれない。 さらに、意思決定システムを考えるときには、 技術の評価方法を一歩引いて見直す必要がある。 この視点の変化に伴う多くの帰結の中でも、 精度 がめったに適切な指標ではないことが分かる。 たとえば、予測を行動に変換するときには、 さまざまな誤り方のコスト感度を考慮したくなることが多い。 ある種類の画像誤分類が人種的なごまかしと受け取られうる一方で、 別のカテゴリへの誤分類は無害だとしたら、 社会的価値を反映して 意思決定プロトコルの設計における閾値を調整したくなるだろう。 また、予測システムがフィードバックループを生みうる点にも 注意が必要である。 たとえば、予測的警備システムを考えてみよう。 これは、予測された犯罪率が高い地域に 警察官の巡回を割り当てるものである。 次のような懸念すべきパターンが生じるのは容易に想像できる。
犯罪の多い地域にはより多くの巡回が行われる。
その結果、これらの地域でより多くの犯罪が発見され、将来の反復で利用可能な訓練データに入る。
より多くの陽性例にさらされることで、モデルはこれらの地域でさらに多くの犯罪を予測する。
次の反復では、更新されたモデルが同じ地域をさらに強く標的にし、さらに多くの犯罪が発見される、という具合に続く。
しばしば、モデルの予測が訓練データと結びつくさまざまな仕組みは、 モデリング過程で考慮されていない。 研究者が runaway feedback loops と呼ぶものにつながる可能性がある。 さらに、そもそも正しい問題を解いているのかどうかにも 注意を払う必要がある。 予測アルゴリズムは今や、 情報の流通を媒介するうえで非常に大きな役割を果たしている。 個人が目にするニュースは、 その人が Like した Facebook ページの集合によって 決まるべきだろうか? 機械学習のキャリアで遭遇しうる 数多くの差し迫った倫理的ジレンマのほんの一部にすぎない。
4.7.6. まとめ¶
多くの場合、訓練セットとテストセットは同じ分布から来ない。分布シフトと呼ばれる。 リスクとは、真の分布から得られるデータ全体にわたる損失の期待値である。しかし、このデータ全体は通常利用できない。経験リスクは、リスクを近似するための訓練データ上の平均損失である。実際には、経験リスク最小化を行う。
対応する仮定の下では、共変量シフトとラベルシフトはテスト時に検出・補正できる。この偏りを考慮しないと、テスト時に問題が生じる可能性がある。 場合によっては、環境が自動化された行動を記憶し、予想外の形で応答することがある。モデルを構築するときにはこの可能性を考慮し、ライブシステムを継続的に監視して、モデルと環境が予期しない形で絡み合う可能性を受け入れる必要がある。
4.7.7. 演習¶
検索エンジンの挙動を変えると何が起こりうるだろうか。ユーザーはどうするだろうか。広告主はどうだろうか。
共変量シフト検出器を実装せよ。ヒント:分類器を作る。
共変量シフト補正器を実装せよ。
分布シフト以外に、経験リスクがリスクをどの程度近似するかに影響しうるものは何だろうか。