21.2. MovieLens データセット¶
推薦研究に利用できるデータセットはいくつもある。その中でも、MovieLens データセットはおそらく最もよく知られたものの一つだろう。MovieLens は、非営利の Web ベースの映画推薦システムである。 1997 年に作成され、ミネソタ大学の研究室である GroupLens によって、研究目的で映画の評価データを収集するために運用されている。MovieLens のデータは、個人化推薦や社会心理学を含む多くの研究において重要な役割を果たしてきた。
21.2.1. データの取得¶
MovieLens データセットは
GroupLens の Web
サイトで公開されている。いくつかの版があるが、ここでは MovieLens 100K
データセットを使用する
(Herlocker et al., 1999)。このデータセットは、943
人のユーザによる 1682 本の映画に対する \(100,000\)
件の評価から構成され、評価値は 1 から 5
までの星評価である。各ユーザが少なくとも 20
本の映画を評価するように整備されている。ユーザやアイテムに関する年齢、性別、ジャンルなどの簡単な属性情報も利用できる。ml-100k.zip
をダウンロードして、u.data
ファイルを展開する。このファイルには、\(100,000\) 件すべての評価が
csv
形式で含まれている。フォルダ内には他にも多くのファイルがあり、各ファイルの詳細な説明はデータセットの
README
ファイルにある。
まず、この節の実験を実行するために必要なパッケージをインポートしよう。
import os
import pandas as pd
from mxnet import gluon, np
from d2l import mxnet as d2l
次に、MovieLens 100k データセットをダウンロードし、相互作用を
DataFrame として読み込みる。
#@save
d2l.DATA_HUB['ml-100k'] = (
'https://files.grouplens.org/datasets/movielens/ml-100k.zip',
'cd4dcac4241c8a4ad7badc7ca635da8a69dddb83')
#@save
def read_data_ml100k():
data_dir = d2l.download_extract('ml-100k')
names = ['user_id', 'item_id', 'rating', 'timestamp']
data = pd.read_csv(os.path.join(data_dir, 'u.data'), sep='\t',
names=names, engine='python')
num_users = data.user_id.unique().shape[0]
num_items = data.item_id.unique().shape[0]
return data, num_users, num_items
21.2.2. データセットの統計¶
データを読み込み、最初の 5 件のレコードを手動で確認してみよう。データ構造を理解し、正しく読み込まれていることを確認するのに有効である。
data, num_users, num_items = read_data_ml100k()
sparsity = 1 - len(data) / (num_users * num_items)
print(f'number of users: {num_users}, number of items: {num_items}')
print(f'matrix sparsity: {sparsity:f}')
print(data.head(5))
Downloading ../data/ml-100k.zip from https://files.grouplens.org/datasets/movielens/ml-100k.zip...
number of users: 943, number of items: 1682
matrix sparsity: 0.936953
user_id item_id rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596
各行は 4 つの列からなり、「user id」1-943、「item
id」1-1682、「rating」1-5、および「timestamp」を含んでいることがわかる。ユーザ数を
\(n\)、アイテム数を \(m\) とすると、サイズ \(n \times m\)
の相互作用行列を構成できる。このデータセットは既存の評価のみを記録しているので、評価行列と呼ぶこともできる。行列の値が正確な評価値を表す場合には、相互作用行列と評価行列を同義に扱う。評価行列の値の大部分は未知である。なぜなら、ユーザは映画の大半を評価していないからである。また、このデータセットの疎性も示している。疎性は
1 - 非ゼロ要素数 / ( ユーザ数 * アイテム数)
と定義される。明らかに、この相互作用行列は非常に疎である(すなわち、疎性
=
93.695%)。実世界のデータセットではさらに高い疎性に悩まされることがあり、推薦システム構築における長年の課題となってきた。実用的な解決策としては、ユーザ/アイテムの特徴量などの追加の側情報を用いて疎性を緩和する方法がある。
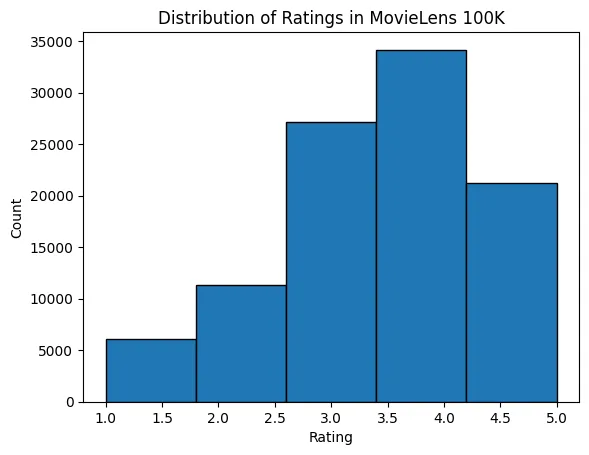
次に、さまざまな評価値の件数分布を描画する。予想どおり、正規分布のように見え、評価の多くは 3〜4 に集中している。
d2l.plt.hist(data['rating'], bins=5, ec='black')
d2l.plt.xlabel('Rating')
d2l.plt.ylabel('Count')
d2l.plt.title('Distribution of Ratings in MovieLens 100K')
d2l.plt.show()
21.2.3. データセットの分割¶
データセットを訓練セットとテストセットに分割する。以下の関数は、random
と seq-aware の 2 つの分割モードを提供する。random
モードでは、timestamp を考慮せずに 100k
件の相互作用をランダムに分割し、デフォルトではデータの 90%
を訓練サンプル、残りの 10%
をテストサンプルとして使用する。seq-aware
モードでは、ユーザが最も最近に評価したアイテムをテスト用に取り除き、ユーザの過去の相互作用を訓練セットとする。ユーザの過去の相互作用は、timestamp
に基づいて古いものから新しいものへと並べ替えられる。このモードは、系列を考慮した推薦の節で使用する。
#@save
def split_data_ml100k(data, num_users, num_items,
split_mode='random', test_ratio=0.1):
"""Split the dataset in random mode or seq-aware mode."""
if split_mode == 'seq-aware':
train_items, test_items, train_list = {}, {}, []
for line in data.itertuples():
u, i, rating, time = line[1], line[2], line[3], line[4]
train_items.setdefault(u, []).append((u, i, rating, time))
if u not in test_items or test_items[u][-1] < time:
test_items[u] = (i, rating, time)
for u in range(1, num_users + 1):
train_list.extend(sorted(train_items[u], key=lambda k: k[3]))
test_data = [(key, *value) for key, value in test_items.items()]
train_data = [item for item in train_list if item not in test_data]
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
else:
mask = [True if x == 1 else False for x in np.random.uniform(
0, 1, (len(data))) < 1 - test_ratio]
neg_mask = [not x for x in mask]
train_data, test_data = data[mask], data[neg_mask]
return train_data, test_data
実際には、テストセットだけでなく検証セットも用いるのがよい実践である。ただし、簡潔さのためここでは省略する。この場合、テストセットはホールドアウトした検証セットとみなすことができる。
21.2.4. データの読み込み¶
データセットを分割した後、便宜上、訓練セットとテストセットをリストおよび辞書/行列に変換する。以下の関数は
DataFrame を行ごとに読み込み、ユーザ/アイテムのインデックスを 0
から始まるように付け直す。その後、ユーザ、アイテム、評価のリストと、相互作用を記録する辞書/行列を返す。フィードバックの種類は
explicit または implicit に指定できる。
#@save
def load_data_ml100k(data, num_users, num_items, feedback='explicit'):
users, items, scores = [], [], []
inter = np.zeros((num_items, num_users)) if feedback == 'explicit' else {}
for line in data.itertuples():
user_index, item_index = int(line[1] - 1), int(line[2] - 1)
score = int(line[3]) if feedback == 'explicit' else 1
users.append(user_index)
items.append(item_index)
scores.append(score)
if feedback == 'implicit':
inter.setdefault(user_index, []).append(item_index)
else:
inter[item_index, user_index] = score
return users, items, scores, inter
その後、上記の手順をまとめて、次節で使用する。結果は Dataset と
DataLoader でラップされる。なお、訓練データに対する DataLoader
の last_batch は rollover
モード(残りのサンプルを次のエポックに繰り越す)に設定し、順序はシャッフルする。
#@save
def split_and_load_ml100k(split_mode='seq-aware', feedback='explicit',
test_ratio=0.1, batch_size=256):
data, num_users, num_items = read_data_ml100k()
train_data, test_data = split_data_ml100k(
data, num_users, num_items, split_mode, test_ratio)
train_u, train_i, train_r, _ = load_data_ml100k(
train_data, num_users, num_items, feedback)
test_u, test_i, test_r, _ = load_data_ml100k(
test_data, num_users, num_items, feedback)
train_set = gluon.data.ArrayDataset(
np.array(train_u), np.array(train_i), np.array(train_r))
test_set = gluon.data.ArrayDataset(
np.array(test_u), np.array(test_i), np.array(test_r))
train_iter = gluon.data.DataLoader(
train_set, shuffle=True, last_batch='rollover',
batch_size=batch_size)
test_iter = gluon.data.DataLoader(
test_set, batch_size=batch_size)
return num_users, num_items, train_iter, test_iter
21.2.5. まとめ¶
MovieLens データセットは推薦研究で広く使われている。公開されており、無料で利用できる。
後続の節で利用するために、MovieLens 100k データセットをダウンロードして前処理する関数を定義した。
21.2.6. 演習¶
これに似た他の推薦データセットにはどのようなものがあるか?
MovieLens についてさらに詳しく知るために、https://movielens.org/ のサイトを見てみよう。