17.3. Q学習¶
前節では、遷移関数や報酬関数など、完全なマルコフ決定過程(MDP)へのアクセスを必要とする価値反復アルゴリズムを扱った。この節では、MDPを必ずしも既知としなくても価値関数を学習できるアルゴリズムであるQ学習 (Watkins and Dayan, 1992) を取り上げる。このアルゴリズムは、強化学習の中心的な考え方、すなわちエージェント自身がデータを収集するという発想を体現している。
17.3.1. Q学習アルゴリズム¶
値反復 における行動価値関数の価値反復は、次の更新式に対応する。
前述のとおり、このアルゴリズムを実装するにはMDP、特に遷移関数 \(P(s' \mid s, a)\) を知る必要がある。Q学習の鍵となる考え方は、上式における \(s' \in \mathcal{S}\) 全体での和を、エージェントが実際に訪れた状態に基づく和で置き換えることである。これにより、遷移関数を明示的に知る必要がなくなる。
17.3.2. Q学習の背後にある最適化問題¶
エージェントが方策 \(\pi_e(a \mid s)\) に従って行動するとしよう。前章と同様に、\(T\) タイムステップからなる \(n\) 本の軌跡 \(\{ (s_t^i, a_t^i)_{t=0,\ldots,T-1}\}_{i=1,\ldots, n}\) から構成されるデータセットを収集する。価値反復は、異なる状態と行動における行動価値 \(Q^*(s, a)\) を相互に結び付ける制約の集合とみなせる。エージェントが \(\pi_e\) を用いて収集したデータを使えば、価値反復の近似版を次のように実装できる。
まず、この式と上の価値反復との類似点と相違点を見よう。もしエージェントの方策 \(\pi_e\) が最適方策 \(\pi^*\) と一致し、さらに無限量のデータを収集できるなら、この最適化問題は価値反復の背後にある最適化問題と同一になる。しかし、価値反復では \(P(s' \mid s, a)\) を知る必要があるのに対し、この目的関数にはその項が現れない。これはごまかしではない。エージェントが状態 \(s_t^i\) で方策 \(\pi_e\) に従って行動 \(a_t^i\) を選ぶとき、次状態 \(s_{t+1}^i\) は遷移関数から生成されたサンプルである。したがって、この目的関数も遷移関数に依存しているが、それはエージェントが収集したデータという形で暗黙的に与えられているのである。
この最適化問題の変数は、すべての \(s \in \mathcal{S}\) と \(a \in \mathcal{A}\) に対する \(Q(s, a)\) である。目的関数の最小化には勾配降下法を用いられる。データセット中の各組 \((s_t^i, a_t^i)\) について、次のように書ける。
ここで \(\alpha\) は学習率である。実際の問題では、エージェントが目標地点に到達すると軌跡は終了することが多い。このような終端状態の価値は0である。なぜなら、その状態以降はもはや行動を取らないからである。このような状態を扱うため、更新式を次のように修正する必要がある。
ここで \(\mathbb{1}_{s_{t+1}^i \textrm{ is terminal}}\) は指示変数であり、\(s_{t+1}^i\) が終端状態なら1、それ以外なら0である。データセットに含まれない状態-行動対 \((s, a)\) の値は \(-\infty\) に設定する。このアルゴリズムはQ学習として知られている。
これらの更新の解 \(\hat{Q}\)、すなわち最適価値関数 \(Q^*\) の近似が得られれば、この価値関数に対応する最適な決定論的方策は容易に得られる。
同じ最適価値関数に対応する決定論的方策が複数存在する場合もある。そのような同値性は任意に解消してよい。いずれも同じ価値関数を持つからである。
17.3.3. Q学習における探索¶
データ収集に用いる方策 \(\pi_e\) は、Q学習がうまく機能するうえで重要である。結局のところ、遷移関数 \(P(s' \mid s, a)\) による \(s'\) に関する期待値を、エージェントが収集したデータで置き換えているのである。もし方策 \(\pi_e\) が状態-行動空間の多様な領域に到達しないなら、推定値 \(\hat{Q}\) は最適な \(Q^*\) の不十分な近似になりやすい。このとき、\(\pi_e\) によって訪れた状態だけでなく、すべての状態 \(s \in \mathcal{S}\) における \(Q^*\) の推定も悪化しうる点が重要である。Q学習の目的関数(あるいは価値反復)は、すべての状態-行動対の価値を結び付ける制約だからである。したがって、データ収集のために適切な方策 \(\pi_e\) を選ぶことが極めて重要である。
この懸念は、\(\mathcal{A}\) から一様ランダムに行動をサンプルする完全にランダムな方策 \(\pi_e\) を選ぶことで緩和できる。そのような方策は最終的にはすべての状態を訪れるが、十分に探索するまでには大量の軌跡を要する。
ここで、Q学習における第2の重要な考え方である探索に至る。Q学習の典型的な実装では、現在の \(Q\) の推定値と方策 \(\pi_e\) を結び付けて、次のように定める。
ここで \(\epsilon\) は探索パラメータであり、ユーザが選ぶ。方策 \(\pi_e\) は探索方策と呼ばれる。この特定の \(\pi_e\) は、現在の推定値 \(\hat{Q}\) に基づく最適行動を確率 \(1-\epsilon\) で選び、残りの確率 \(\epsilon\) でランダムに探索するため、\(\epsilon\)-greedy 探索方策と呼ばれる。いわゆるsoftmax探索方策も利用できる。
ここでハイパーパラメータ \(T\) は温度と呼ばれる。\(\epsilon\)-greedy 方策における大きな \(\epsilon\) は、softmax 方策における大きな温度 \(T\) と同様の役割を果たす。
現在の行動価値関数の推定値 \(\hat{Q}\) に依存する探索を用いる場合、最適化問題を定期的に解き直す必要がある点に注意されたい。Q学習の典型的な実装では、\(\pi_e\) を用いて各時刻に行動を選んだ後、収集済みデータセット中のいくつかの状態-行動対(通常は直前のタイムステップで収集したもの)を使って1回のミニバッチ更新を行う。
17.3.4. Q学習の「自己修正」特性¶
Q学習の過程でエージェントが収集するデータセットは、時間とともに増加する。探索方策 \(\pi_e\) も推定値 \(\hat{Q}\) も、より多くのデータを収集するにつれて変化する。ここから、Q学習がうまく機能する理由について重要な洞察が得られる。状態 \(s\) を考えよう。ある行動 \(a\) が現在の推定値 \(\hat{Q}(s,a)\) の下で大きな値を持つなら、\(\epsilon\)-greedy 探索方策でも softmax 探索方策でも、その行動を選ぶ確率は高くなる。もしその行動が実際には望ましい行動ではないなら、その行動の結果として到達する将来状態は低い報酬しかもたらさない。したがって、次のQ学習目的関数の更新で \(\hat{Q}(s,a)\) の値は下がり、次にエージェントが状態 \(s\) を訪れたときにその行動を選ぶ確率も低下する。悪い行動、たとえば \(\hat{Q}(s,a)\) において過大評価されている行動は、エージェントによって探索されるが、Q学習目的関数の次の更新でその値が修正される。一方、良い行動、たとえば \(\hat{Q}(s, a)\) が大きい行動は、より頻繁に探索され、その結果として強化される。この性質を用いると、Q学習はランダムな方策 \(\pi_e\) から始めたとしても最適方策に収束しうることを示せる (Watkins and Dayan, 1992)。
新しいデータを収集するだけでなく、適切な種類のデータを収集する能力こそが強化学習アルゴリズムの中心的特徴であり、これが教師あり学習との違いである。深層ニューラルネットワークを用いたQ学習(後のDQNの章で扱う)は、強化学習の再興を支えた (Mnih et al., 2013)。
17.3.5. Q学習の実装¶
ここでは、Open AI Gym のFrozenLakeに対してQ学習を実装する方法を示す。設定は 値反復 の実験と同じである。
%matplotlib inline
import numpy as np
import random
from d2l import torch as d2l
seed = 0 # 乱数生成器のシード
gamma = 0.95 # 割引率
num_iters = 256 # 反復回数
alpha = 0.9 # 学習率
epsilon = 0.9 # ε-greedy法におけるε
random.seed(seed) # 乱数シードを設定する
np.random.seed(seed)
# 環境を設定する。
env_info = d2l.make_env('FrozenLake-v1', seed=seed)
FrozenLake環境では、エージェントは \(4 \times 4\) のグリッド上を移動する。各マスが状態に対応し、行動として「上」(\(\uparrow\))、「下」(\(\rightarrow\))、「左」(\(\leftarrow\))、「右」(\(\rightarrow\)) を取る。環境にはいくつかの穴(H)のマス、凍ったマス(F)、そして目標マス(G)が含まれるが、これらはすべてエージェントには未知である。問題を簡単にするため、エージェントの行動は確定的である、すなわちすべての \(s \in \mathcal{S}, a \in \mathcal{A}\) に対して \(P(s' \mid s, a) = 1\) と仮定する。エージェントが目標に到達すると試行は終了し、行動に関係なく報酬 \(1\) を受け取る。それ以外の状態での報酬は、どの行動に対しても \(0\) である。目的は、与えられた開始位置(S)(すなわち \(s_0\))から目標位置(G)に到達する方策を学習し、収益を最大化することである。
まず、\(\epsilon\)-greedy 法を次のように実装する。
def e_greedy(env, Q, s, epsilon):
if random.random() < epsilon:
return env.action_space.sample()
else:
return np.argmax(Q[s,:])
これでQ学習を実装する準備が整った。
def q_learning(env_info, gamma, num_iters, alpha, epsilon):
env_desc = env_info['desc'] # 2D array specifying what each grid item means
env = env_info['env'] # 2D array specifying what each grid item means
num_states = env_info['num_states']
num_actions = env_info['num_actions']
Q = np.zeros((num_states, num_actions))
V = np.zeros((num_iters + 1, num_states))
pi = np.zeros((num_iters + 1, num_states))
for k in range(1, num_iters + 1):
# 環境をリセットする
state, done = env.reset(), False
while not done:
# 与えられた状態に対して行動を選択し,選択した行動に基づいて環境で行動する
action = e_greedy(env, Q, state, epsilon)
next_state, reward, done, _ = env.step(action)
# Q-update:
y = reward + gamma * np.max(Q[next_state,:])
Q[state, action] = Q[state, action] + alpha * (y - Q[state, action])
# 次の状態へ遷移する
state = next_state
# 可視化のためにのみ最大値と最大行動を記録する
for s in range(num_states):
V[k,s] = np.max(Q[s,:])
pi[k,s] = np.argmax(Q[s,:])
d2l.show_Q_function_progress(env_desc, V[:-1], pi[:-1])
q_learning(env_info=env_info, gamma=gamma, num_iters=num_iters, alpha=alpha, epsilon=epsilon)
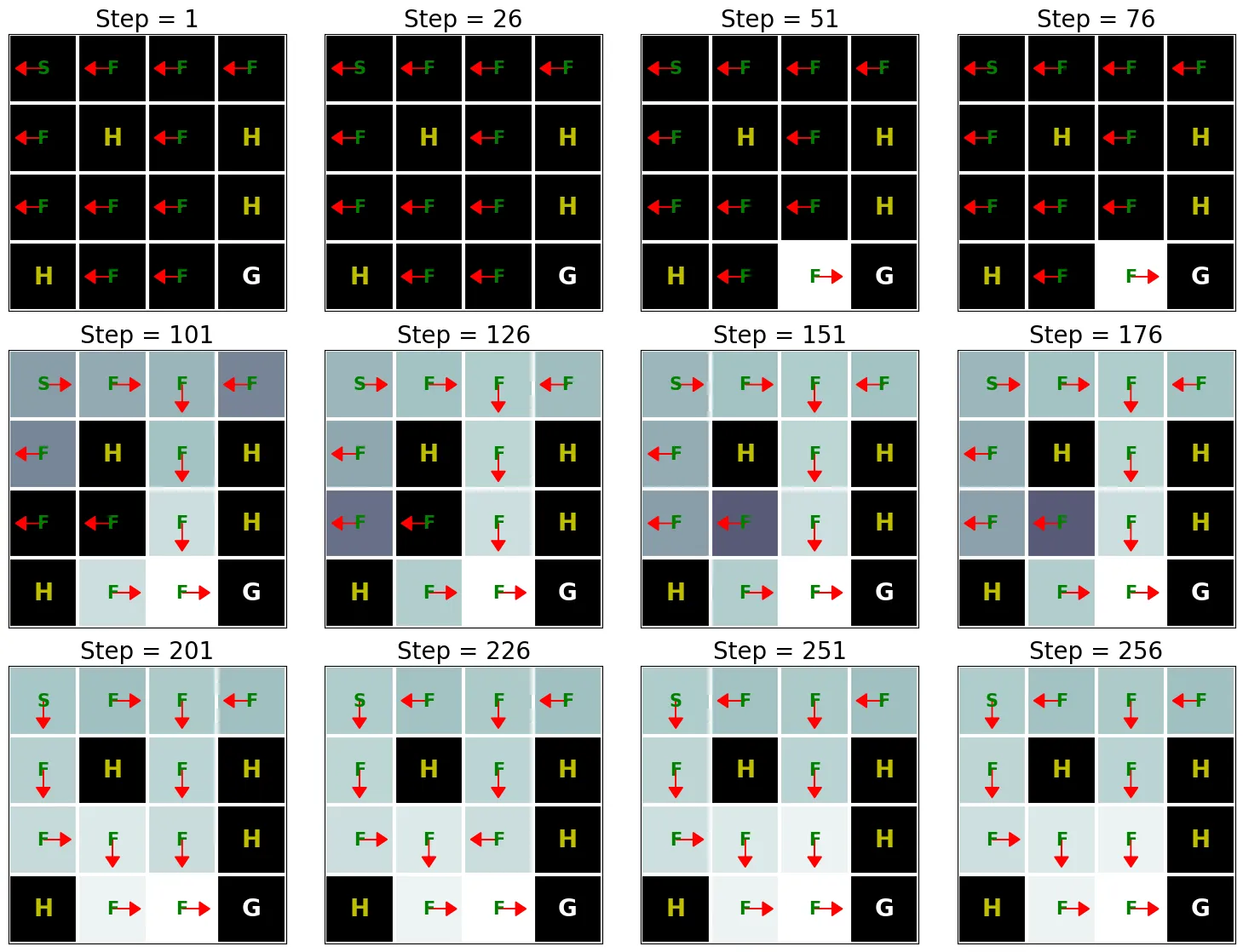
この結果から、Q学習は約250回の反復後にこの問題の最適解を見つけられることがわかる。しかし、この結果を価値反復アルゴリズムの結果(値反復の実装 を参照)と比較すると、価値反復アルゴリズムのほうがはるかに少ない反復回数で最適解に到達する。これは、価値反復アルゴリズムが完全なMDPにアクセスできるのに対し、Q学習はそうではないためである。
17.3.6. まとめ¶
Q学習は、最も基本的な強化学習アルゴリズムの1つである。近年の強化学習の成功、特にビデオゲームをプレイする学習において中心的な役割を果たしてきた (Mnih et al., 2013)。Q学習の実装には、マルコフ決定過程(MDP)、たとえば遷移関数や報酬関数を完全に知っている必要はない。
17.3.7. 演習¶
グリッドサイズを \(8 \times 8\) に増やしてみよ。\(4 \times 4\) グリッドと比べて、最適価値関数を見つけるのに何回の反復が必要か。
Q学習アルゴリズムを、\(\gamma\)(すなわち上のコードの “gamma”)を \(0\)、\(0.5\)、\(1\) にした場合について再度実行し、結果を分析せよ。
Q学習アルゴリズムを、\(\epsilon\)(すなわち上のコードの “epsilon”)を \(0\)、\(0.5\)、\(1\) にした場合について再度実行し、結果を分析せよ。