13.2. 非同期計算¶
今日のコンピュータは高度に並列なシステムであり、複数の CPU コア(多くの場合、各コアに複数のスレッド)、GPU あたり複数の処理要素、そしてしばしばデバイスあたり複数の GPU から構成されている。要するに、多くの異なる処理を同時に、しばしば異なるデバイス上で実行できる。残念ながら、Python は並列・非同期コードを書くのにあまり向いていない。少なくとも、何らかの追加の助けなしにはそうである。結局のところ、Python は単一スレッドであり、将来これが変わる可能性は低いだろう。MXNet や TensorFlow のような深層学習フレームワークは性能を向上させるために 非同期プログラミング モデルを採用しているが、 PyTorch は Python 自身のスケジューラを利用しており、そのため性能上のトレードオフが異なる。 PyTorch では、デフォルトで GPU 操作は非同期である。GPU を使う関数を呼び出すと、その操作は特定のデバイスにキューイングされるが、必ずしもすぐに実行されるとは限らない。これにより、CPU や他の GPU 上の操作を含め、より多くの計算を並列に実行できる。
したがって、非同期プログラミングの仕組みを理解することは、計算要件や相互依存を事前に減らすことで、より効率的なプログラムを開発する助けになる。これにより、メモリオーバーヘッドを削減し、プロセッサの利用率を高めることができる。
from d2l import torch as d2l
import numpy, os, subprocess
import torch
from torch import nn
from d2l import mxnet as d2l
import numpy, os, subprocess
from mxnet import autograd, gluon, np, npx
from mxnet.gluon import nn
npx.set_np()
13.2.1. バックエンドによる非同期性¶
準備運動として、次の簡単な問題を考えよう。乱数行列を生成して、それを掛け合わせたいとする。NumPy
と PyTorch のテンソルの両方でそれを行い、違いを見てみよう。
なお、PyTorch の tensor は GPU 上に定義されている。
# GPU計算のウォームアップ
device = d2l.try_gpu()
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('torch'):
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
numpy: 0.9937 sec
torch: 0.0019 sec
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('mxnet.np'):
for _ in range(10):
a = np.random.normal(size=(1000, 1000))
b = np.dot(a, a)
numpy: 0.8821 sec
mxnet.np: 0.0222 sec
[07:01:48] ../src/storage/storage.cc:196: Using Pooled (Naive) StorageManager for CPU
PyTorch 経由のベンチマーク結果は桁違いに高速である。 NumPy のドット積は CPU プロセッサ上で実行される一方、 PyTorch の行列積は GPU 上で実行されるため、後者がはるかに高速であることは予想される。しかし、この大きな時間差は、何か別のことが起きていることを示唆している。 デフォルトでは、PyTorch では GPU 操作は非同期である。 PyTorch にすべての計算を返却前に完了させるよう強制すると、以前何が起きていたかが分かる。つまり、フロントエンドが Python に制御を返している間に、計算はバックエンドで実行されているのである。
with d2l.Benchmark():
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
torch.cuda.synchronize(device)
Done: 0.0025 sec
with d2l.Benchmark():
for _ in range(10):
a = np.random.normal(size=(1000, 1000))
b = np.dot(a, a)
npx.waitall()
Done: 1.1622 sec
大まかに言えば、PyTorch にはユーザーとの直接的なやり取りを行うフロントエンド(たとえば Python 経由)と、計算を実行するためにシステムが用いるバックエンドがある。 図 13.2.1 に示すように、ユーザーは Python や C++ など、さまざまなフロントエンド言語で PyTorch プログラムを書くことができる。どのフロントエンド言語を使っても、PyTorch プログラムの実行は主として C++ 実装のバックエンドで行われる。フロントエンド言語から発行された操作は、実行のためにバックエンドへ渡される。 バックエンドは独自のスレッドを管理し、キューに入ったタスクを継続的に収集して実行する。 これが機能するためには、バックエンドが計算グラフ内の さまざまなステップ間の依存関係を追跡できなければならないことに注意しようう。 したがって、互いに依存する操作を並列化することはできない。
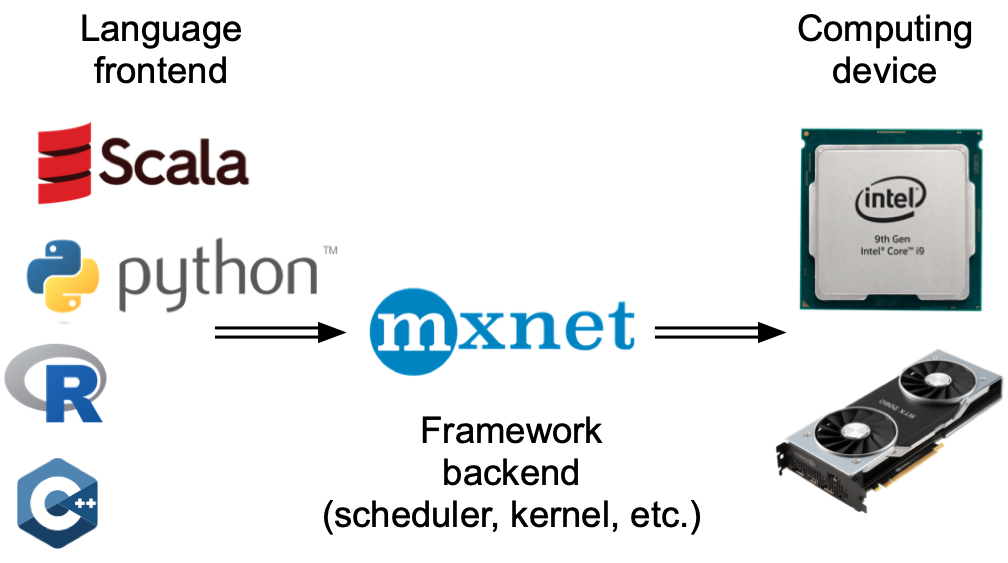
図 13.2.1 Programming language frontends and deep learning framework backends.¶
依存グラフをもう少しよく理解するために、別の簡単な例を見てみよう。
x = torch.ones((1, 2), device=device)
y = torch.ones((1, 2), device=device)
z = x * y + 2
z
tensor([[3., 3.]], device='cuda:0')
x = np.ones((1, 2))
y = np.ones((1, 2))
z = x * y + 2
z
array([[3., 3.]])

図 13.2.2 The backend tracks dependencies between various steps in the computational graph.¶
上のコード片は 図 13.2.2 にも示されている。 Python
フロントエンドのスレッドが最初の 3
つの文のいずれかを実行すると、単にタスクをバックエンドのキューに返すだけである。最後の文の結果を
表示 する必要があるとき、Python フロントエンドのスレッドは C++
バックエンドのスレッドが変数 z
の結果の計算を終えるまで待機する。この設計の利点の 1 つは、Python
フロントエンドのスレッドが実際の計算を行う必要がないことである。したがって、Python
の性能にかかわらず、プログラム全体の性能への影響は小さくなる。
図 13.2.3
はフロントエンドとバックエンドの相互作用を示している。

図 13.2.3 Interactions of the frontend and backend.¶
13.2.2. バリアとブロッカー¶
13.2.3. 計算の改善¶
13.2.4. まとめ¶
深層学習フレームワークは、Python フロントエンドを実行バックエンドから分離することがある。これにより、コマンドをバックエンドへ高速に非同期投入でき、それに伴う並列性が得られる。
非同期性により、フロントエンドはかなり応答性が高くなる。ただし、タスクキューを埋めすぎると過剰なメモリ消費につながる可能性があるため注意が必要である。フロントエンドとバックエンドをおおむね同期させるために、ミニバッチごとに同期することが推奨される。
チップベンダーは、深層学習の効率について、よりきめ細かな洞察を得るための高度な性能解析ツールを提供している。
13.2.5. 演習¶
CPU 上で、この節と同じ行列積演算をベンチマークしなさい。バックエンドによる非同期性はまだ観測できるか。