17.2. 値反復¶
この節では、軌跡の リターン を最大化するために、各状態でロボットが選択すべき最良の行動をどのように決定するかを扱う。値反復(Value Iteration)と呼ばれるアルゴリズムを説明し、凍った湖の上を移動するシミュレートされたロボットに対して実装する。
17.2.1. 確率的方策¶
\(\pi(a \mid s)\) で表す確率的方策(以下、単に方策)は、状態 \(s \in \mathcal{S}\) が与えられたときの行動 \(a \in \mathcal{A}\) に関する条件付き分布であり、\(\pi(a \mid s) \equiv P(a \mid s)\) である。たとえば、ロボットが4つの行動 \(\mathcal{A}=\) {左へ進む, 下へ進む, 右へ進む, 上へ進む} を持つとする。このとき、状態 \(s \in \mathcal{S}\) における方策は、この4つの行動に対するカテゴリ分布であり、その確率が \([0.4, 0.2, 0.1, 0.3]\) であるかもしれない。別の状態 \(s' \in \mathcal{S}\) では、同じ4つの行動に対する確率 \(\pi(a \mid s')\) が \([0.1, 0.1, 0.2, 0.6]\) であるかもしれない。任意の状態 \(s\) に対して、\(\sum_a \pi(a \mid s) = 1\) が成り立たなければならない。決定論的方策は確率的方策の特殊な場合であり、\(\pi(a \mid s)\) がただ1つの特定の行動にのみ非ゼロの確率を割り当てる。たとえば、上の4行動の例では \([1, 0, 0, 0]\) である。
記法を簡潔にするため、以後はしばしば \(\pi(a \mid s)\) の代わりに条件付き分布を \(\pi(s)\) と書く。
17.2.2. 価値関数¶
ロボットが状態 \(s_0\) から開始し、各時刻でまず方策から行動をサンプルして \(a_t \sim \pi(s_t)\) とし、その行動を実行して次の状態 \(s_{t+1}\) に遷移すると考える。軌跡 \(\tau = (s_0, a_0, r_0, s_1, a_1, r_1, \ldots)\) は、中間時刻でどの行動 \(a_t\) がサンプルされるかによって変化しうる。このようなすべての軌跡にわたる平均 リターン \(R(\tau) = \sum_{t=0}^\infty \gamma^t r(s_t, a_t)\) を
と定義する。
ここで、\(s_{t+1} \sim P(s_{t+1} \mid s_t, a_t)\) はロボットの次状態であり、\(r(s_t, a_t)\) は時刻 \(t\) に状態 \(s_t\) で行動 \(a_t\) を取ったときに得られる即時報酬である。\(V^\pi\) は方策 \(\pi\) に対する価値関数と呼ばれる。要するに、状態 \(s_0\) の価値 \(V^\pi(s_0)\) とは、ロボットが状態 \(s_0\) から開始し、各時刻で方策 \(\pi\) に従って行動したときに得られる期待 \(\gamma\) 割引 リターン である。
次に、軌跡を2段階に分ける。(i) 第1段階は、行動 \(a_0\) を取って \(s_0 \to s_1\) と遷移する部分、(ii) 第2段階は、その後の軌跡 \(\tau' = (s_1, a_1, r_1, \ldots)\) である。強化学習のあらゆるアルゴリズムの背後にある重要な考え方は、状態 \(s_0\) の価値を、第1段階で得られる平均報酬と、ありうる次状態 \(s_1\) にわたる価値関数の平均として表せるという点にある。これはきわめて直観的であり、マルコフ仮定から導かれる。すなわち、現在の状態からの平均リターンは、次状態からの平均リターンと、次状態へ遷移することで得られる平均報酬の和である。数学的には、2段階への分解を次のように書ける。
この分解は非常に強力である。これは動的計画法の原理の基礎であり、すべての強化学習アルゴリズムはこれに依拠する。第2段階には2つの期待値があることに注意されたい。1つは、確率的方策に従って第1段階で選ぶ行動 \(a_0\) に関する期待であり、もう1つは、その行動の結果として到達しうる状態 \(s_1\) に関する期待である。マルコフ決定過程(MDP)の遷移確率を用いると、(17.2.2) は次のように書ける。
重要なのは、この等式がすべての状態 \(s \in \mathcal{S}\) で成り立つことである。なぜなら、その状態から始まる任意の軌跡を考え、それを2段階に分解できるからである。
17.2.3. 行動価値関数¶
実装では、しばしば行動価値関数と呼ばれる量を保持すると便利である。これは価値関数と密接に関係する量であり、\(s_0\) から始まる軌跡の平均 リターン を表す。ただし、第1段階の行動を \(a_0\) に固定して定義する。
期待値の内側の総和が \(t=1,\ldots,\infty\) から始まっているのは、この場合、第1段階の報酬が固定されているからである。ここでも軌跡を2段階に分けると、次のように書ける。
これは、行動価値関数に対する (17.2.3) の対応物である。
17.2.4. 最適確率的方策¶
価値関数も行動価値関数も、ロボットが採用する方策に依存する。そこで、平均 リターン を最大化する最適方策を考える。
ロボットが取りうるすべての確率的方策の中で、最適方策 \(\pi^*\) は、状態 \(s_0\) から始まる軌跡に対して最大の平均割引 リターン を達成する。最適方策の価値関数と行動価値関数を、それぞれ \(V^* \equiv V^{\pi^*}\) および \(Q^* \equiv Q^{\pi^*}\) と表す。
任意の状態において、方策の下で選ばれる行動が1つだけである決定論的方策を考えると、次が得られる。
この式は、状態 \(s\) における最適行動(決定論的方策の場合)が、第1段階の報酬 \(r(s, a)\) と、第2段階で到達しうるすべての次状態 \(s'\) にわたって平均した、次状態 \(s'\) から始まる軌跡の平均 リターン との和を最大化する行動であることを意味する。
17.2.5. 動的計画法の原理¶
前節の (17.2.2) および (17.2.5) における導出は、それぞれ最適価値関数 \(V^*\) または最適行動価値関数 \(Q^*\) を計算するアルゴリズムへと変換できる。次が成り立つ。
最適方策 \(\pi^*\) が決定論的であれば、状態 \(s\) で選ばれる行動は1つだけなので、次のようにも書ける。
これはすべての状態 \(s \in \mathcal{S}\) に対して成り立つ。この等式は「動的計画法の原理」と呼ばれる (Bellman, 1952, Bellman, 1957)。1950年代に Richard Bellman によって定式化され、「最適軌跡の残りの部分もまた最適である」と要約できる。
17.2.6. 値反復¶
動的計画法の原理から、最適価値関数を求めるアルゴリズム、すなわち値反復を導ける。値反復の重要な考え方は、この等式を、異なる状態 \(s \in \mathcal{S}\) における \(V^*(s)\) を結びつける制約条件の集合として捉えることである。まず、すべての状態 \(s \in \mathcal{S}\) に対して、価値関数を任意の値 \(V_0(s)\) で初期化する。\(k\) 回目の反復では、値反復アルゴリズムは価値関数を次のように更新する。
\(k \to \infty\) とすると、初期化 \(V_0\) に依らず、値反復アルゴリズムで推定した価値関数は最適価値関数に収束する。
同じ値反復アルゴリズムは、行動価値関数を用いて次のようにも等価に書ける。
この場合、すべての \(s \in \mathcal{S}\) と \(a \in \mathcal{A}\) に対して \(Q_0(s, a)\) を任意の値で初期化する。やはり、すべての \(s \in \mathcal{S}\) と \(a \in \mathcal{A}\) に対して \(Q^*(s, a) = \lim_{k \to \infty} Q_k(s, a)\) が成り立つ。
17.2.7. 方策評価¶
値反復により、最適な決定論的方策 \(\pi^*\) の最適価値関数、すなわち \(V^{\pi^*}\) を計算できる。同様の反復更新を用いれば、他の任意の方策 \(\pi\)(確率的方策でもよい)に対応する価値関数も計算できる。ここでも、すべての状態 \(s \in \mathcal{S}\) に対して \(V^\pi_0(s)\) を任意の値で初期化し、\(k\) 回目の反復で次の更新を行う。
このアルゴリズムは方策評価として知られており、与えられた方策に対する価値関数の計算に用いられる。ここでも、\(k \to \infty\) とすると、初期化 \(V_0\) に依らず、これらの更新は正しい価値関数に収束する。
方策 \(\pi\) の行動価値関数 \(Q^\pi(s, a)\) を計算するアルゴリズムも同様に導ける。
17.2.8. 値反復の実装¶
次に、Open AI Gym の FrozenLake と呼ばれるナビゲーション問題に対して、値反復をどのように実装するかを示す。まず、次のコードのように環境を設定する必要がある。
%matplotlib inline
import numpy as np
import random
from d2l import torch as d2l
seed = 0 # 乱数生成器のシード
gamma = 0.95 # 割引率
num_iters = 10 # 反復回数
random.seed(seed) # 結果を再現可能にするため乱数シードを設定する
np.random.seed(seed)
# 環境を設定する。
env_info = d2l.make_env('FrozenLake-v1', seed=seed)
FrozenLake 環境では、ロボットは \(4 \times 4\) のグリッド上を移動する。各マスが状態に対応し、行動は「上」(\(\uparrow\))、「下」(\(\rightarrow\))、「左」(\(\leftarrow\))、「右」(\(\rightarrow\)) である。環境にはいくつかの穴(H)のマス、凍ったマス(F)、そしてゴールのマス(G)があり、これらはすべてロボットには未知である。問題を簡単にするため、ロボットの行動は確定的である、すなわちすべての \(s \in \mathcal{S}, a \in \mathcal{A}\) に対して \(P(s' \mid s, a) = 1\) と仮定する。ロボットがゴールに到達すると試行は終了し、行動に関係なく報酬 \(1\) を受け取る。それ以外の状態での報酬は、どの行動に対しても \(0\) である。ロボットの目的は、与えられた開始位置(S)(これが \(s_0\) である)からゴール位置(G)へ到達する方策を学習し、リターン を最大化することである。
次の関数は値反復を実装する。env_info には MDP
と環境に関する情報が含まれ、gamma は割引率である。
def value_iteration(env_info, gamma, num_iters):
env_desc = env_info['desc'] # 2D array shows what each item means
prob_idx = env_info['trans_prob_idx']
nextstate_idx = env_info['nextstate_idx']
reward_idx = env_info['reward_idx']
num_states = env_info['num_states']
num_actions = env_info['num_actions']
mdp = env_info['mdp']
V = np.zeros((num_iters + 1, num_states))
Q = np.zeros((num_iters + 1, num_states, num_actions))
pi = np.zeros((num_iters + 1, num_states))
for k in range(1, num_iters + 1):
for s in range(num_states):
for a in range(num_actions):
# \sum_{s'} p(s'\mid s,a) [r + \gamma v_k(s')] を計算する
for pxrds in mdp[(s,a)]:
# mdp(s,a): [(p1,次状態1,r1,d1),(p2,次状態2,r2,d2),..]
pr = pxrds[prob_idx] # 状態 s と行動 a に対する次状態 s' の遷移確率 p(s'\mid s,a)
nextstate = pxrds[nextstate_idx] # Next state
reward = pxrds[reward_idx] # Reward
Q[k,s,a] += pr * (reward + gamma * V[k - 1, nextstate])
# 最大値と最大行動を記録する
V[k,s] = np.max(Q[k,s,:])
pi[k,s] = np.argmax(Q[k,s,:])
d2l.show_value_function_progress(env_desc, V[:-1], pi[:-1])
value_iteration(env_info=env_info, gamma=gamma, num_iters=num_iters)
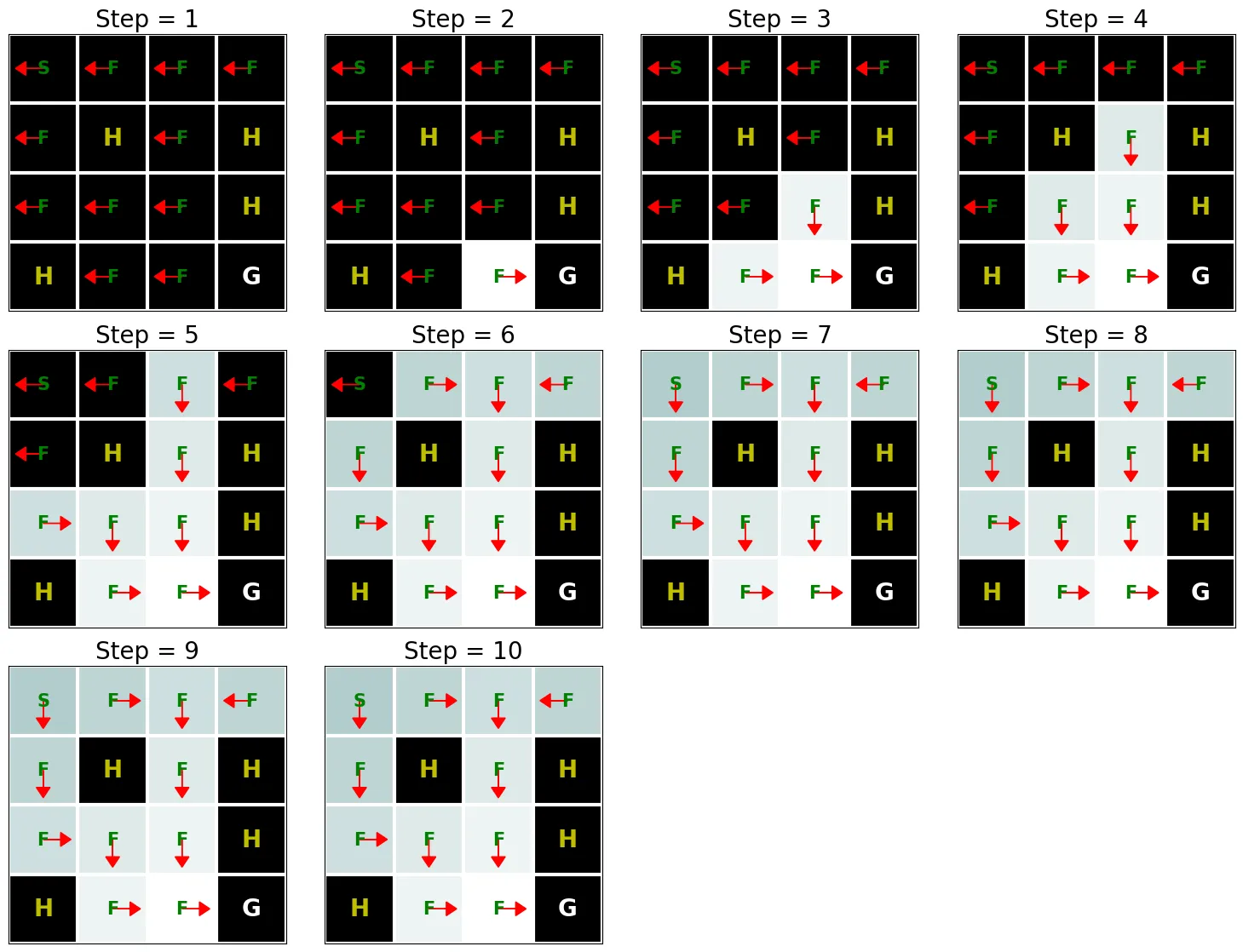
上の図は、方策(矢印は行動を表す)と価値関数(色の変化は、初期値に対応する濃い色から最適値に対応する明るい色へと、価値関数が時間とともにどのように変化するかを表す)を示している。図からわかるように、値反復は10回の反復で最適価値関数を見つけ、H のマスでない限り、どの状態から開始してもゴール状態(G)に到達できる。実装上のもう1つの興味深い点は、最適価値関数を求めるだけでなく、その価値関数に対応する最適方策 \(\pi^*\) も自動的に得られることである。
17.2.9. まとめ¶
値反復アルゴリズムの基本的な考え方は、動的計画法の原理を用いて、与えられた状態から得られる最適な平均リターンを求めることである。なお、値反復アルゴリズムを実装するには、マルコフ決定過程(MDP)を完全に知っている必要があり、たとえば遷移関数や報酬関数が既知でなければならない。
17.2.10. 演習¶
グリッドサイズを \(8 \times 8\) に増やしてみよ。\(4 \times 4\) のグリッドと比べて、最適価値関数を見つけるのに何回の反復が必要か。
値反復アルゴリズムの計算量はどの程度か。
\(\gamma\)(上のコードの “gamma”)を \(0\)、\(0.5\)、\(1\) に設定して再び値反復アルゴリズムを実行し、その結果を分析せよ。
\(\gamma\) の値は、値反復が収束するまでに必要な反復回数にどのような影響を与えるか。\(\gamma=1\) のときはどうなるか。